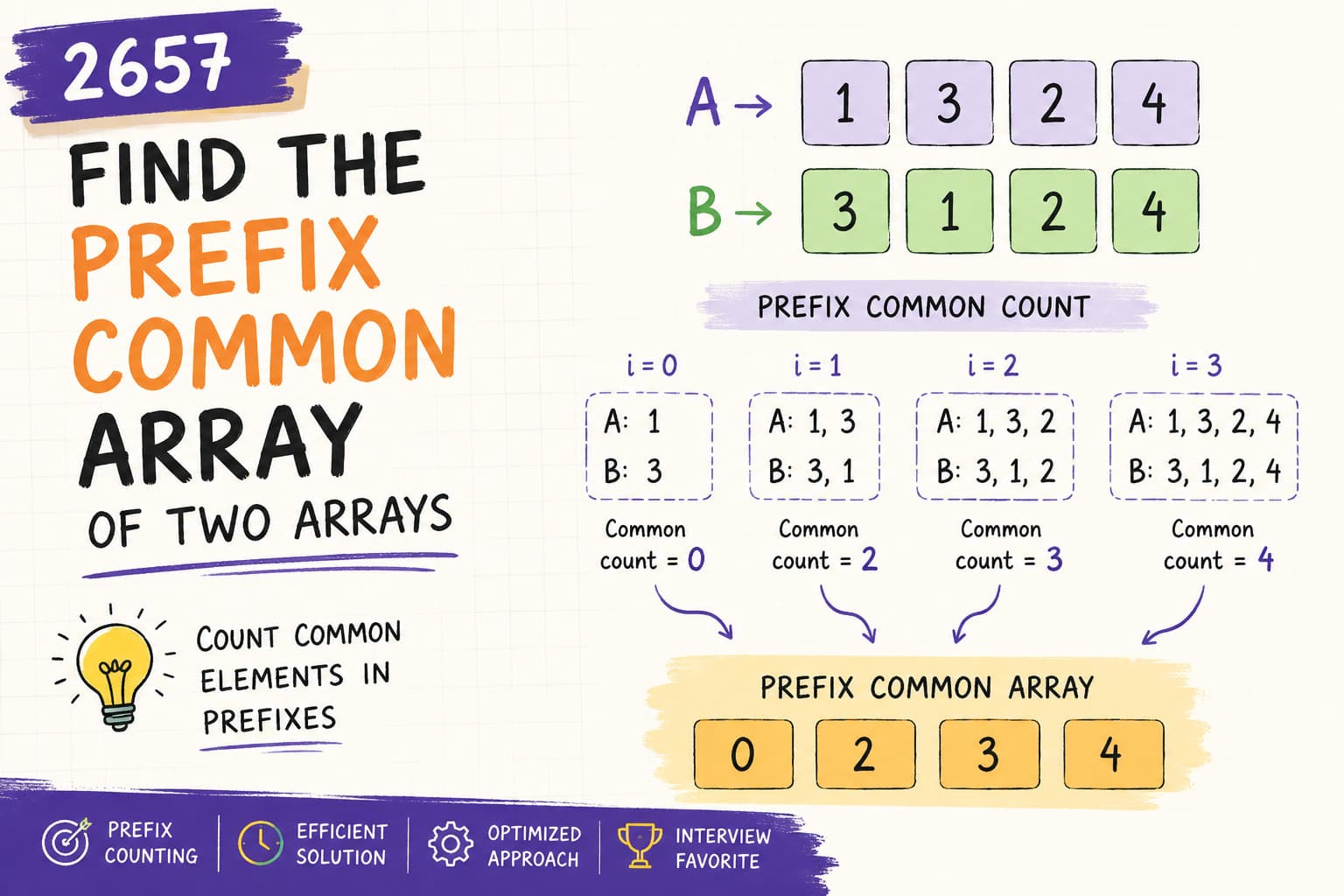
LeetCode 110: Balanced Binary Tree – Java Optimized DFS Solution Explained
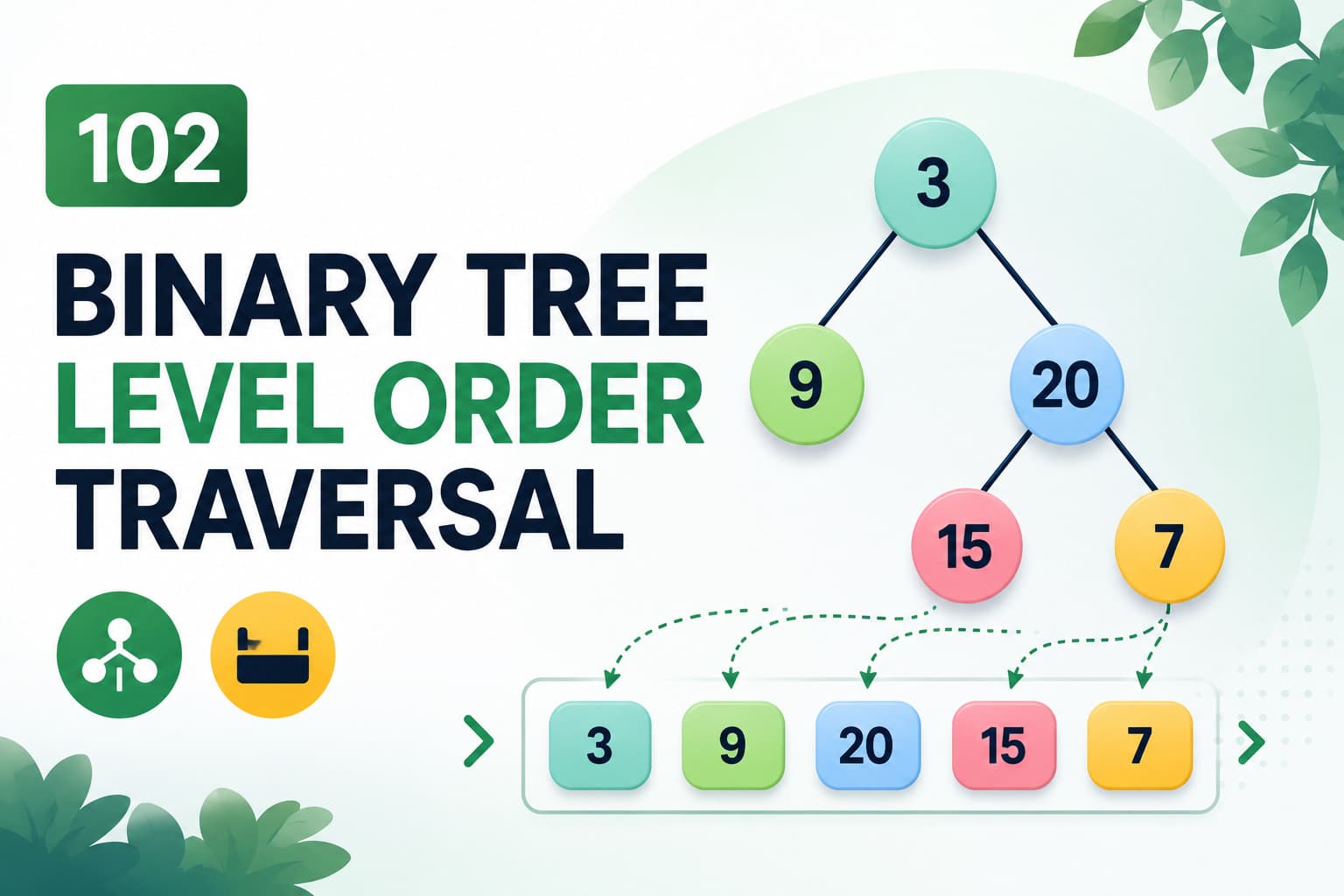
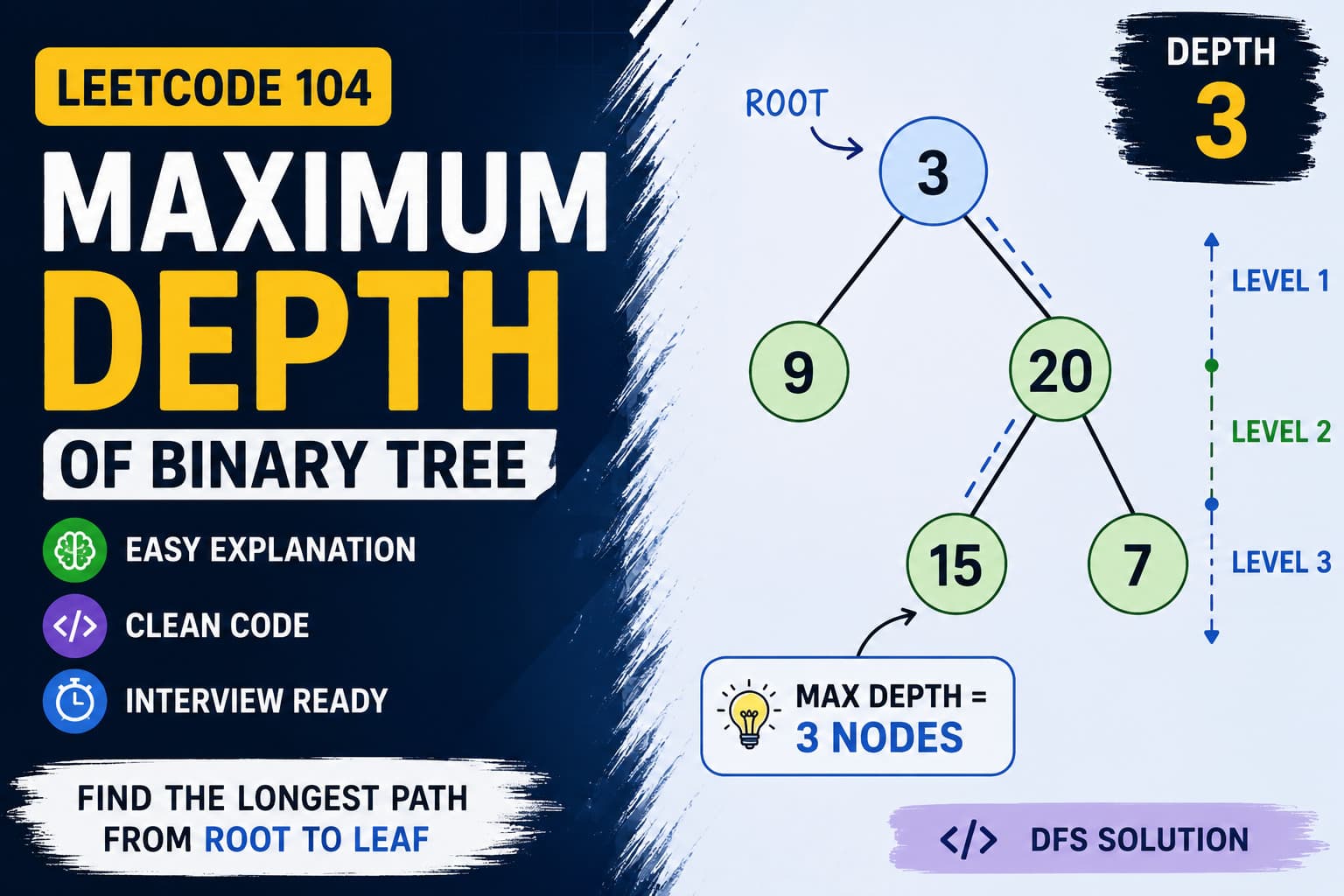
IntroductionLeetCode 110 – Balanced Binary Tree is one of the most important binary tree interview problems.This problem teaches:Tree recursionHeight calculationDepth First Search (DFS)Bottom-up recursionOptimization techniquesIt is frequently asked in coding interviews because it checks whether you can:Traverse trees efficientlyAvoid repeated calculationsCombine recursion with conditionsOptimize brute force tree solutionsThis problem is also a foundation for advanced tree problems like:AVL TreesHeight-balanced treesDiameter of Binary TreeTree DP problemsProblem Link🔗 https://leetcode.com/problems/balanced-binary-tree/Problem StatementGiven the root of a binary tree:Return:trueif the tree is:height-balancedOtherwise return:falseWhat is a Balanced Binary Tree?A binary tree is balanced if:For every node,|height(left subtree) - height(right subtree)| <= 1Meaning:Left and right subtree heights should not differ by more than:1Example 1Inputroot = [3,9,20,null,null,15,7]Tree:3/ \9 20/ \15 7OutputtrueExplanation:Every node satisfies:height difference <= 1Example 2Inputroot = [1,2,2,3,3,null,null,4,4]Tree:1/ \2 2/ \3 3/ \4 4OutputfalseExplanation:Left subtree becomes much deeper than right subtree.Difference becomes greater than:1Key ObservationTo determine if tree is balanced:At every node we need:Height of left subtreeHeight of right subtreeCompare differenceThis naturally becomes a recursive DFS problem.Brute Force ApproachIntuitionFor every node:Calculate left heightCalculate right heightCompare differenceRecursively check childrenBrute Force Java Solutionclass Solution {public int height(TreeNode root) {if(root == null)return 0;return 1 + Math.max(height(root.left), height(root.right));}public boolean isBalanced(TreeNode root) {if(root == null)return true;int left = height(root.left);int right = height(root.right);if(Math.abs(left - right) > 1)return false;return isBalanced(root.left) && isBalanced(root.right);}}Problem with Brute ForceThe height function gets called repeatedly.For every node:Heights are recalculated again and again.This increases complexity significantly.Brute Force ComplexityTime ComplexityO(N²)because height calculation repeats.Space ComplexityO(H)for recursion stack.Optimized DFS ApproachInstead of:Calculating heights separatelyWe can:Calculate height and balance together.Core Optimization IdeaWhile calculating height:If subtree becomes unbalanced:Return negative value immediatelyThis avoids unnecessary computation.Optimized Java Solutionclass Solution {public int solve(TreeNode roo) {if(roo == null)return 0;int left = solve(roo.left);if(left < 0) {return -1;}int right = solve(roo.right);if(right < 0) {return -1;}if(Math.abs(left - right) > 1) {return -1000;}return 1 + Math.max(left, right);}public boolean isBalanced(TreeNode root) {int ans = solve(root);return ans < 0 ? false : true;}}Cleaner Optimized VersionWe can simplify negative returns using:-1consistently.Cleaner Java Solutionclass Solution {public int height(TreeNode root) {if(root == null)return 0;int left = height(root.left);if(left == -1)return -1;int right = height(root.right);if(right == -1)return -1;if(Math.abs(left - right) > 1)return -1;return 1 + Math.max(left, right);}public boolean isBalanced(TreeNode root) {return height(root) != -1;}}Why This WorksAt every node:Recursively calculate left heightRecursively calculate right heightIf difference > 1:Tree is unbalancedPropagate failure upward immediately.Dry RunInput1/ \2 2/ \3 3/ \4 4Step 1Start from leaf nodes:4 → height = 1Step 2Node:3gets:left = 1right = 1Difference:0Balanced.Height:2Step 3At node:2Left height:2Right height:0Difference:2Unbalanced.Return:-1Final ResultTree is:Not balancedReturn:falseTime Complexity AnalysisOptimized DFS SolutionTime ComplexityO(N)because every node is visited once.Space ComplexityO(H)where:H = height of treeWorst case:O(N)for skewed tree.Brute Force vs OptimizedApproachTime ComplexitySpace ComplexityBrute ForceO(N²)O(H)Optimized DFSO(N)O(H)Interview ExplanationIn interviews, explain:Instead of recalculating heights repeatedly, we combine height calculation and balance checking into a single DFS traversal.This demonstrates:Optimization skillsRecursive DFS understandingBottom-up tree processingCommon Mistakes1. Recalculating Heights RepeatedlyThis causes:O(N²)complexity.2. Forgetting Absolute DifferenceAlways use:Math.abs(left - right)3. Not Handling Null NodesBase case:if(root == null)return 0;is necessary.FAQsQ1. What is a balanced binary tree?A tree where left and right subtree heights differ by at most:1for every node.Q2. Why use DFS?Because height calculation naturally follows recursive depth traversal.Q3. Why return -1?It acts as a signal:Subtree already unbalancedQ4. Is this problem important for interviews?Very important.It is one of the most common tree optimization questions.ConclusionLeetCode 110 is an excellent binary tree optimization problem.It teaches:DFS traversalHeight calculationBottom-up recursionOptimization techniquesThe key insight is:Combine balance checking and height calculation in one DFS traversal.Once you understand this optimization pattern, many advanced tree problems become much easier.