Introduction
LeetCode 496 Next Greater Element I is your gateway into one of the most important and frequently tested patterns in coding interviews — the Monotonic Stack. Once you understand this problem deeply, problems like Next Greater Element II, Daily Temperatures, and Largest Rectangle in Histogram all start to make sense.
Here is the Link of Question -: LeetCode 496
This article covers plain English explanation, real life analogy, brute force and optimal approaches in Java, detailed dry runs, complexity analysis, common mistakes, and FAQs.
What Is the Problem Really Asking?
You have two arrays. nums2 is the main array. nums1 is a smaller subset of nums2. For every element in nums1, find its position in nums2 and look to the right — what is the first element that is strictly greater? If none exists, return -1.
Example:
nums1 = [4,1,2],nums2 = [1,3,4,2]- For
4in nums2: elements to its right are[2], none greater →-1 - For
1in nums2: elements to its right are[3,4,2], first greater is3 - For
2in nums2: no elements to its right →-1 - Output:
[-1, 3, -1]
Real Life Analogy — The Taller Person in a Queue
Imagine you are standing in a queue and you want to know — who is the first person taller than you standing somewhere behind you in the line?
You look to your right one by one until you find someone taller. That person is your "next greater element." If everyone behind you is shorter, your answer is -1.
Now imagine doing this for every person in the queue efficiently — instead of each person looking one by one, you use a smart system that processes everyone in a single pass. That smart system is the Monotonic Stack.
Approach 1: Brute Force (Beginner Friendly)
The Idea
For each element in nums1, find its position in nums2, then scan everything to its right to find the first greater element.
java
Simple to understand but inefficient. For each element in nums1 you scan the entire nums2.
Time Complexity: O(m × n) — where m = nums1.length, n = nums2.length Space Complexity: O(1) — ignoring output array
This works for the given constraints (n ≤ 1000) but will not scale for larger inputs. The follow-up specifically asks for better.
Approach 2: Monotonic Stack + HashMap (Optimal Solution) ✅
The Idea
This is your solution and the best one. The key insight is — instead of answering queries for nums1 elements one by one, precompute the next greater element for every element in nums2 and store results in a HashMap. Then answering nums1 queries becomes just a HashMap lookup.
To precompute efficiently, we use a Monotonic Stack — a stack that always stays in decreasing order from bottom to top.
Why traverse from right to left? Because we are looking for the next greater element to the right. Starting from the right end, by the time we process any element, we have already seen everything to its right.
Algorithm:
- Traverse
nums2from right to left - Maintain a stack of "candidate" next greater elements
- For current element, pop all stack elements that are smaller or equal — they can never be the next greater for anything to the left
- If stack is empty → next greater is
-1, else → top of stack is the answer - Push current element onto stack
- Store result in HashMap
- Look up each
nums1element in the HashMap
java
Why Is the Stack Monotonic?
After popping smaller elements, the stack always maintains a decreasing order from bottom to top. This means the top of the stack at any point is always the smallest element seen so far to the right — making it the best candidate for "next greater."
This is called a Monotonic Decreasing Stack and it is the heart of this entire pattern.
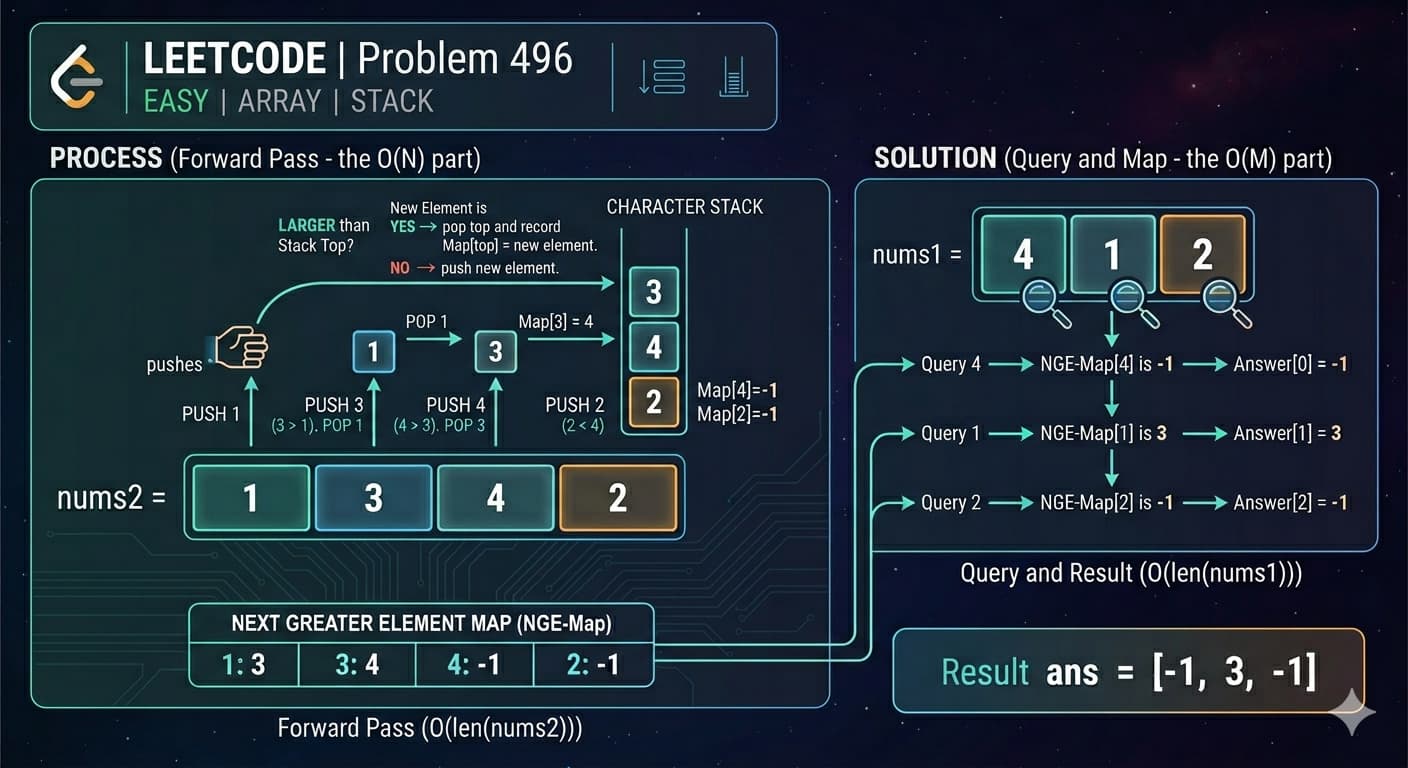
Detailed Dry Run — nums2 = [1,3,4,2]
We traverse from right to left:
i = 3, nums2[3] = 2
- Stack is empty
- No elements to pop
- Stack empty → mp.put(2, -1)
- Push 2 → stack:
[2]
i = 2, nums2[2] = 4
- Stack top is 2, and 4 >= 2 → pop 2 → stack:
[] - Stack empty → mp.put(4, -1)
- Push 4 → stack:
[4]
i = 1, nums2[1] = 3
- Stack top is 4, and 3 < 4 → stop popping
- Stack not empty → mp.put(3, 4)
- Push 3 → stack:
[4, 3]
i = 0, nums2[0] = 1
- Stack top is 3, and 1 < 3 → stop popping
- Stack not empty → mp.put(1, 3)
- Push 1 → stack:
[4, 3, 1]
HashMap after processing nums2:
1 → 3,2 → -1,3 → 4,4 → -1
Now answer nums1 = [4, 1, 2]:
nums1[0] = 4→ mp.get(4) =-1nums1[1] = 1→ mp.get(1) =3nums1[2] = 2→ mp.get(2) =-1
✅ Output: [-1, 3, -1]
Time Complexity: O(n + m) — n for processing nums2, m for answering nums1 queries Space Complexity: O(n) — HashMap and Stack both store at most n elements
Why Pop Elements Smaller Than Current?
This is the most important thing to understand in this problem. When we are at element x and we see a stack element y where y < x, we pop y. Why?
Because x is to the right of everything we will process next (we go right to left), and x is already greater than y. So for any element to the left of x, if they are greater than y, they are definitely also greater than y — meaning y would never be the "next greater" for anything. It becomes useless and gets discarded.
This is why the stack stays decreasing — every element we keep is a legitimate candidate for being someone's next greater element.
How This Differs From Previous Stack Problems
You have been solving stack problems with strings — backspace, stars, adjacent duplicates. This problem introduces the stack for arrays and searching, which is a step up in complexity.
The pattern shift is: instead of using the stack to build or reduce a string, we use it to maintain a window of candidates while scanning. This monotonic stack idea is what powers many hard problems like Largest Rectangle in Histogram, Trapping Rain Water, and Daily Temperatures.
Common Mistakes to Avoid
Using >= instead of > in the pop condition We pop when nums2[i] >= st.peek(). If you use only >, equal elements stay on the stack and give wrong answers since we need strictly greater.
Traversing left to right instead of right to left Going left to right makes it hard to know what is to the right of the current element. Always go right to left for "next greater to the right" problems.
Forgetting HashMap lookup handles the nums1 query efficiently Some people recompute inside the nums1 loop. Always precompute in a HashMap — that is the whole point of the optimization.
FAQs — People Also Ask
Q1. What is a Monotonic Stack and why is it used in LeetCode 496? A Monotonic Stack is a stack that maintains its elements in either increasing or decreasing order. In LeetCode 496, a Monotonic Decreasing Stack is used to efficiently find the next greater element for every number in nums2 in a single pass, reducing time complexity from O(n²) to O(n).
Q2. What is the time complexity of LeetCode 496 optimal solution? The optimal solution runs in O(n + m) time where n is the length of nums2 and m is the length of nums1. Processing nums2 takes O(n) and answering all nums1 queries via HashMap takes O(m).
Q3. Why do we traverse nums2 from right to left? Because we are looking for the next greater element to the right. Starting from the right end means by the time we process any element, we have already seen all elements to its right and stored them in the stack as candidates.
Q4. Is LeetCode 496 asked in coding interviews? Yes, it is commonly used as an introduction to the Monotonic Stack pattern at companies like Amazon, Google, and Microsoft. It often appears as a warmup before harder follow-ups like Next Greater Element II (circular array) or Daily Temperatures.
Q5. What is the difference between LeetCode 496 and LeetCode 739 Daily Temperatures? Both use the same Monotonic Stack pattern. In 496 you return the actual next greater value. In 739 you return the number of days (index difference) until a warmer temperature. The core stack logic is identical.
Similar LeetCode Problems to Practice Next
- 739. Daily Temperatures — Medium — days until warmer temperature, same pattern
- 503. Next Greater Element II — Medium — circular array version
- 901. Online Stock Span — Medium — monotonic stack with span counting
- 84. Largest Rectangle in Histogram — Hard — classic monotonic stack
- 42. Trapping Rain Water — Hard — monotonic stack or two pointer
Conclusion
LeetCode 496 Next Greater Element I is the perfect entry point into the Monotonic Stack pattern. The brute force is easy to understand, but the real learning happens when you see why the stack stays decreasing and how that single insight collapses an O(n²) problem into O(n).
Once you truly understand why we pop smaller elements and how the HashMap bridges the gap between precomputation and query answering, the entire family of Next Greater Element problems becomes approachable — including the harder circular and histogram variants.