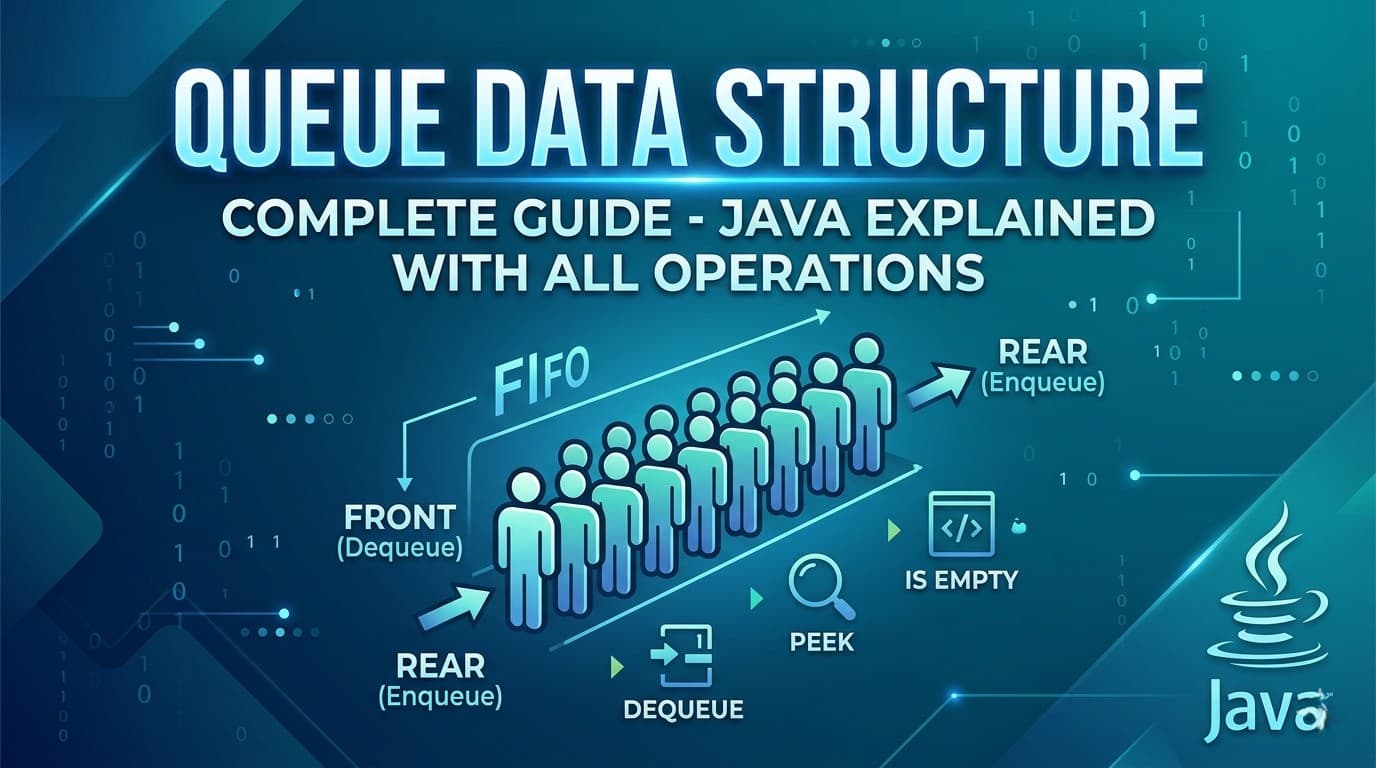
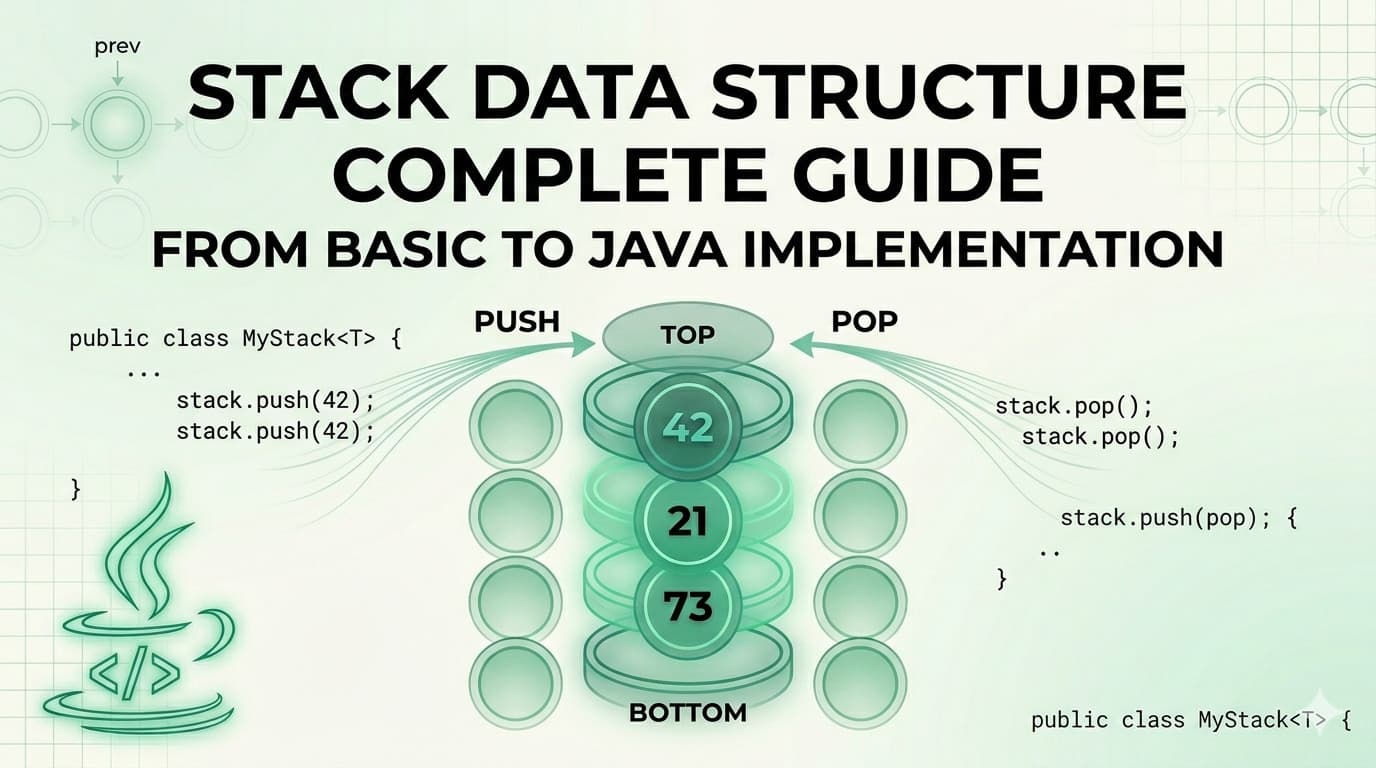
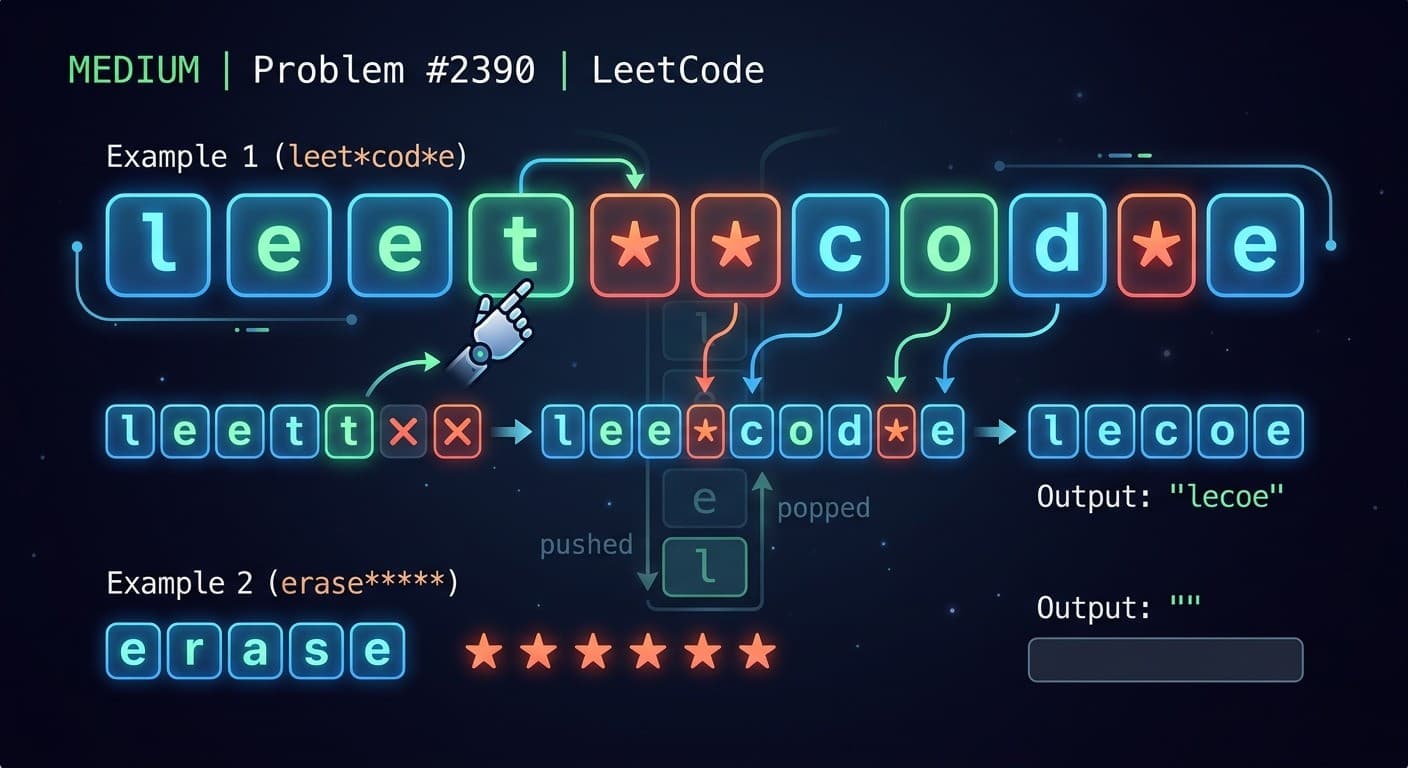
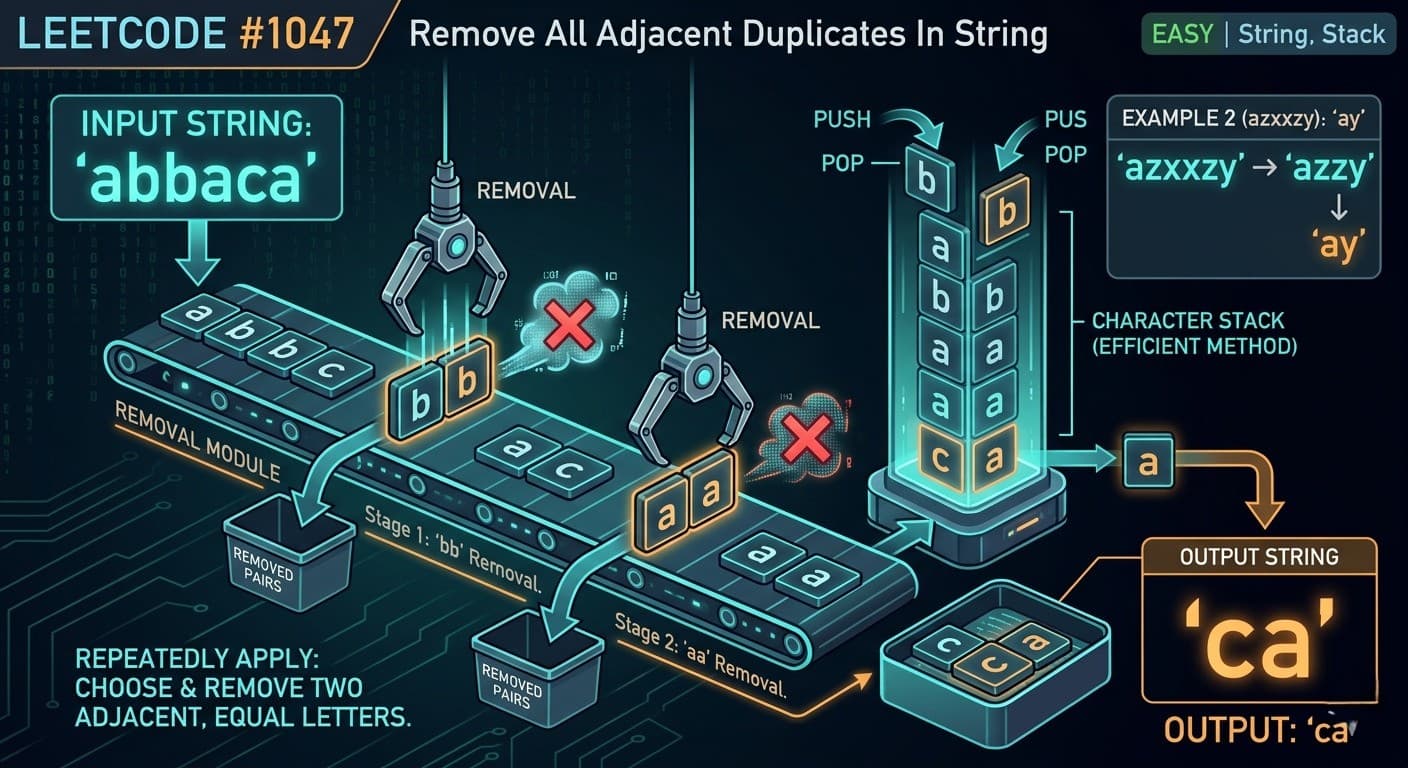
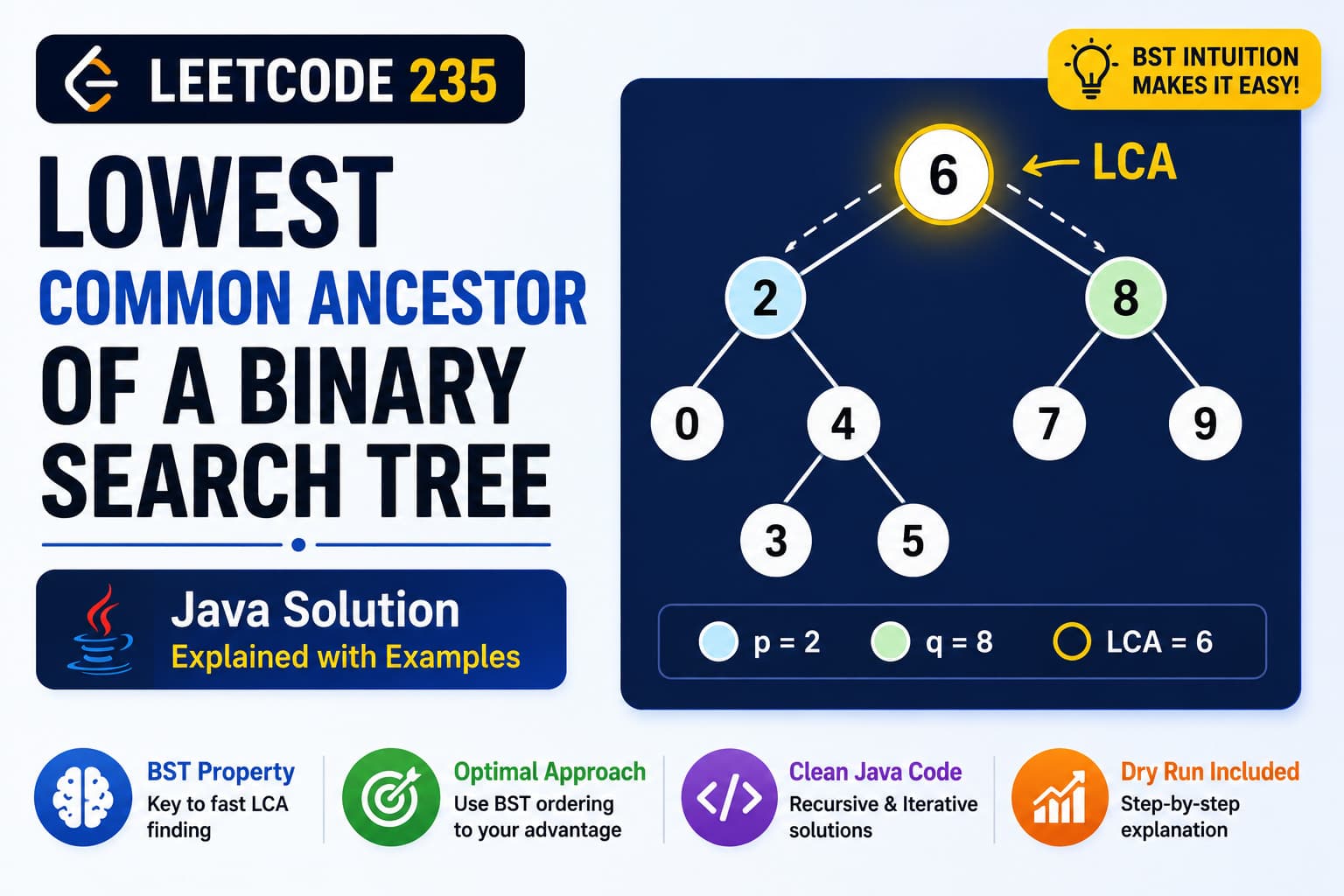
OOPs in Java - Complete Guide With Simple Examples
IntroductionObject Oriented Programming — or OOPs — is the foundation of Java. Almost every Java program you will ever write or read is built around OOPs concepts. The good news is these concepts are not complicated at all. They are actually modeled after how we think about real life things.By the end of this article you will understand every core OOPs concept clearly — not just enough to answer interview questions, but enough to actually use them confidently in your code.What Is Object Oriented Programming?Before OOPs, programmers wrote procedural code — a long sequence of instructions executed top to bottom. As programs grew bigger, this became a nightmare to manage. You could not organize related data and behavior together, reuse code cleanly, or model real world things naturally.OOPs solved this by organizing code around objects — just like the real world is organized around things. A car, a person, a bank account — each is a thing with properties and behaviors. OOPs lets you model these things directly in code.Java is a purely object oriented language (almost everything in Java is an object). That is why understanding OOPs is not optional in Java — it is essential.Class — The BlueprintA class is a blueprint or template. It defines what properties and behaviors an object of that type will have. The class itself is not an actual thing — it is just the design.Think of a class like an architectural blueprint of a house. The blueprint is not a house. But from one blueprint you can build many houses.class Car { // properties (what a car HAS) String brand; String color; int speed; // behaviors (what a car DOES) void accelerate() { System.out.println(brand + " is speeding up!"); } void brake() { System.out.println(brand + " is slowing down!"); }}Car is the blueprint. It defines that every car has a brand, color, speed, and can accelerate and brake. No actual car exists yet — this is just the design.Object — The Real ThingAn object is an actual instance created from a class. When you create an object, you are building a real house from the blueprint.public class Main { public static void main(String[] args) { // creating objects from the Car class Car car1 = new Car(); car1.brand = "Toyota"; car1.color = "Red"; car1.speed = 120; Car car2 = new Car(); car2.brand = "BMW"; car2.color = "Black"; car2.speed = 200; car1.accelerate(); // Toyota is speeding up! car2.brake(); // BMW is slowing down! }}car1 and car2 are two different objects from the same Car blueprint. Each has its own data but shares the same structure and behaviors.Constructor — The Object InitializerA constructor is a special method that runs automatically when an object is created. It is used to set initial values.class Car { String brand; String color; int speed; // constructor — same name as class, no return type Car(String brand, String color, int speed) { this.brand = brand; this.color = color; this.speed = speed; } void accelerate() { System.out.println(brand + " is speeding up!"); }}// Now creating objects is cleanerCar car1 = new Car("Toyota", "Red", 120);Car car2 = new Car("BMW", "Black", 200);The this keyword refers to the current object — it distinguishes between the parameter brand and the object's field brand.The Four Pillars of OOPsEverything in OOPs builds on four core concepts. These are what interviewers ask about and what real code is organized around.Pillar 1: Encapsulation — Wrapping and Protecting DataEncapsulation means bundling data (fields) and the methods that work on that data together in one class — and controlling access from outside.Think of a capsule pill. The medicine inside is protected by the outer shell. You do not mess with the medicine directly — you just swallow the capsule.In Java, encapsulation is achieved using access modifiers (private, public) and getters/setters.class BankAccount { private double balance; // private — no direct access from outside private String owner; BankAccount(String owner, double initialBalance) { this.owner = owner; this.balance = initialBalance; } // getter — read the balance public double getBalance() { return balance; } // setter with validation — controlled access public void deposit(double amount) { if (amount > 0) { balance += amount; System.out.println("Deposited: " + amount); } else { System.out.println("Invalid amount!"); } } public void withdraw(double amount) { if (amount > 0 && amount <= balance) { balance -= amount; } else { System.out.println("Insufficient funds!"); } }}BankAccount account = new BankAccount("Alice", 1000);// account.balance = -5000; // ERROR — private, cannot access directlyaccount.deposit(500); // controlled access through methodSystem.out.println(account.getBalance()); // 1500.0Why encapsulation matters: Without it, anyone could set balance = -999999 directly. With it, you control exactly how data can be changed — protecting your object's integrity.Pillar 2: Inheritance — Reusing Code Through Parent-Child RelationshipInheritance allows one class to acquire the properties and behaviors of another class. The child class gets everything the parent has and can add its own things on top.Think of it like genetics. A child inherits traits from their parents but also develops their own unique characteristics.In Java, inheritance uses the extends keyword.// Parent classclass Animal { String name; Animal(String name) { this.name = name; } void eat() { System.out.println(name + " is eating."); } void sleep() { System.out.println(name + " is sleeping."); }}// Child class inherits from Animalclass Dog extends Animal { String breed; Dog(String name, String breed) { super(name); // calls Animal's constructor this.breed = breed; } // Dog's own behavior void bark() { System.out.println(name + " says: Woof!"); }}class Cat extends Animal { Cat(String name) { super(name); } void meow() { System.out.println(name + " says: Meow!"); }}Dog dog = new Dog("Buddy", "Labrador");dog.eat(); // inherited from Animal — Buddy is eating.dog.sleep(); // inherited from Animal — Buddy is sleeping.dog.bark(); // Dog's own method — Buddy says: Woof!Cat cat = new Cat("Whiskers");cat.eat(); // inherited — Whiskers is eating.cat.meow(); // Cat's own — Whiskers says: Meow!super() calls the parent class constructor. super.methodName() calls a parent class method.Why inheritance matters: You write eat() and sleep() once in Animal and every animal class gets them for free. No repetition, clean organization.Pillar 3: Polymorphism — One Interface, Many FormsPolymorphism means the same method name behaves differently depending on the object calling it. It comes in two flavors.The word itself means "many forms" — same action, different results based on who is doing it.Think of a "speak" command given to different animals. You tell a dog to speak — it barks. You tell a cat to speak — it meows. Same command, different behavior.Method Overriding (Runtime Polymorphism)A child class provides its own version of a method already defined in the parent class.class Animal { String name; Animal(String name) { this.name = name; } void makeSound() { System.out.println(name + " makes a sound."); }}class Dog extends Animal { Dog(String name) { super(name); } @Override void makeSound() { System.out.println(name + " says: Woof!"); }}class Cat extends Animal { Cat(String name) { super(name); } @Override void makeSound() { System.out.println(name + " says: Meow!"); }}class Cow extends Animal { Cow(String name) { super(name); } @Override void makeSound() { System.out.println(name + " says: Moo!"); }}Animal[] animals = { new Dog("Buddy"), new Cat("Whiskers"), new Cow("Bella")};for (Animal a : animals) { a.makeSound(); // different behavior for each!}// Buddy says: Woof!// Whiskers says: Meow!// Bella says: Moo!Same makeSound() call on an Animal reference — but the actual behavior depends on what the object really is at runtime. That is runtime polymorphism.Method Overloading (Compile-Time Polymorphism)Same method name, different parameters in the same class.class Calculator { int add(int a, int b) { return a + b; } double add(double a, double b) { return a + b; } int add(int a, int b, int c) { return a + b + c; }}Calculator calc = new Calculator();calc.add(2, 3); // calls first method — 5calc.add(2.5, 3.5); // calls second method — 6.0calc.add(1, 2, 3); // calls third method — 6Java decides which version to call at compile time based on the argument types and count.Pillar 4: Abstraction — Hiding Complexity, Showing EssentialsAbstraction means showing only the necessary details to the user and hiding the internal complexity. You expose what something does, not how it does it.Think of driving a car. You know the steering wheel turns the car and the pedal accelerates it. You do not need to know how the engine combustion works internally. The complexity is hidden — only what you need to use is exposed.Java achieves abstraction through abstract classes and interfaces.Abstract ClassAn abstract class cannot be instantiated directly. It can have abstract methods (no body — child must implement) and regular methods (with body).abstract class Shape { String color; Shape(String color) { this.color = color; } // abstract method — no body, child MUST implement abstract double calculateArea(); // regular method — shared behavior void displayColor() { System.out.println("Color: " + color); }}class Circle extends Shape { double radius; Circle(String color, double radius) { super(color); this.radius = radius; } @Override double calculateArea() { return Math.PI * radius * radius; }}class Rectangle extends Shape { double width, height; Rectangle(String color, double width, double height) { super(color); this.width = width; this.height = height; } @Override double calculateArea() { return width * height; }}Shape circle = new Circle("Red", 5);Shape rect = new Rectangle("Blue", 4, 6);circle.displayColor(); // Color: RedSystem.out.println(circle.calculateArea()); // 78.53...System.out.println(rect.calculateArea()); // 24.0InterfaceAn interface is a 100% abstract contract — it only defines what methods a class must have, with no implementation (in older Java). A class can implement multiple interfaces.interface Flyable { void fly(); // every class implementing this MUST define fly()}interface Swimmable { void swim();}class Duck implements Flyable, Swimmable { @Override public void fly() { System.out.println("Duck is flying!"); } @Override public void swim() { System.out.println("Duck is swimming!"); }}Duck duck = new Duck();duck.fly(); // Duck is flying!duck.swim(); // Duck is swimming!Key difference between abstract class and interface:A class can extend only one abstract class but can implement multiple interfaces. Use abstract class when classes share common code. Use interface when you want to define a contract that unrelated classes can follow.Access Modifiers — Quick ReferenceAccess modifiers control who can access your class members:ModifierSame ClassSame PackageSubclassEverywhereprivate✅❌❌❌default✅✅❌❌protected✅✅✅❌public✅✅✅✅General rule — make fields private, make methods public unless there is a reason not to. This is encapsulation in practice.Quick Summary — All OOPs Concepts in One PlaceClass — Blueprint/template that defines structure and behaviorObject — Real instance created from a class using newConstructor — Special method that initializes an object when createdEncapsulation — Bundle data and methods together, control access with private/publicInheritance — Child class gets parent's properties and behaviors using extendsPolymorphism — Same method name behaves differently (overriding = runtime, overloading = compile time)Abstraction — Hide complexity, show only essentials using abstract class or interfaceFAQs — People Also AskQ1. What is the difference between a class and an object in Java? A class is the blueprint — it defines structure but does not exist in memory as a usable thing. An object is a real instance created from that blueprint using new. You can create many objects from one class, just like building many houses from one blueprint.Q2. What is the difference between abstract class and interface in Java? An abstract class can have both abstract (no body) and concrete (with body) methods, and a class can extend only one. An interface traditionally has only abstract methods and a class can implement multiple interfaces. Use abstract class for shared code, interface for defining contracts.Q3. What is the difference between method overriding and overloading? Overriding happens in a parent-child relationship — the child redefines a parent method with the same name and parameters. Overloading happens in the same class — same method name but different parameters. Overriding is resolved at runtime, overloading at compile time.Q4. Why is OOPs important in Java? Java is built entirely around OOPs. Every piece of Java code lives inside a class. OOPs enables code reuse through inheritance, data protection through encapsulation, flexibility through polymorphism, and simplicity through abstraction — all essential for building large, maintainable applications.ConclusionOOPs in Java is not a collection of confusing terms — it is a natural way of thinking about and organizing code. Classes are blueprints, objects are real things, encapsulation protects data, inheritance reuses code, polymorphism provides flexibility, and abstraction hides complexity.Once these four pillars feel natural, you will start seeing them everywhere — in every Java library, every framework, every codebase. That is when Java truly starts to click.