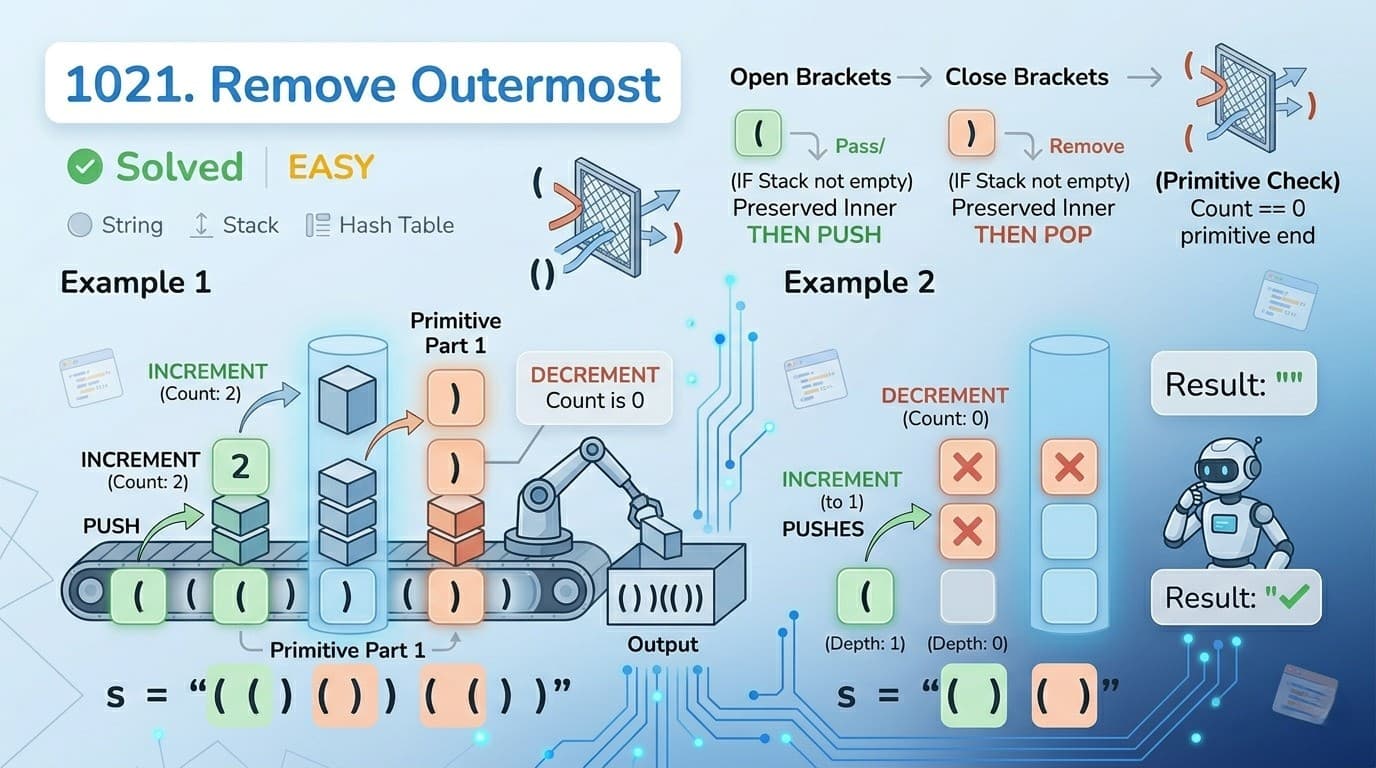
LeetCode 3612: Process String with Special Operations I – Java StringBuilder Solution Explained
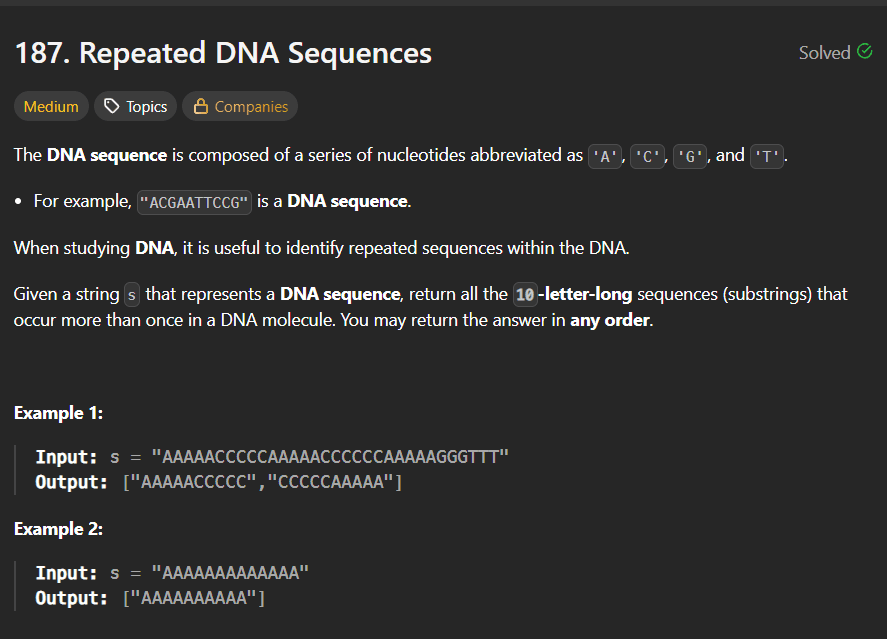
IntroductionLeetCode 3612, Process String with Special Operations I, is an excellent string simulation problem that tests your ability to process characters sequentially while maintaining a dynamic result string.The challenge introduces three special operations:* → Delete the last character# → Duplicate the current string% → Reverse the current stringAlthough the problem appears simple, it teaches an important interview concept:Simulate operations exactly as described while efficiently modifying a string.In this article, we'll break down the intuition, explore the optimal approach, perform a dry run, and analyze the time and space complexity.Problem link :- Process String with Special Operations IProblem StatementYou are given a string s containing:Lowercase English letters*#%Process the string from left to right according to the following rules:Lowercase LetterAppend it to the result.a → result += 'a'Asterisk (*)Remove the last character if one exists.abc*becomesabHash (#)Duplicate the current string.abc#becomesabcabcPercent (%)Reverse the current string.abc%becomescbaReturn the final string after processing all characters.Example 1Inputs = "a#b%*"Step-by-Step ExecutionCharacterOperationResultaAppenda#DuplicateaabAppendaab%Reversebaa*Remove lastbaOutput"ba"Key ObservationThe operations always modify the current result.We need a data structure that supports:Appendappend()Delete Last CharacterdeleteCharAt()Reversereverse()Duplicateappend(currentString)A StringBuilder supports all of these efficiently.This makes it the perfect choice for the problem.Approach 1: StringBuilder SimulationIntuitionProcess each character one by one.If it is a letterAppend it.If it is *Delete the last character.If it isDuplicate the entire current string.If it is %Reverse the current string.Continue until all characters are processed.Java Solutionclass Solution { public String processStr(String q) { StringBuilder s = new StringBuilder(); for(int i =0;i < q.length();i++){ if(q.charAt(i) != '#'&&q.charAt(i) != '*'&& q.charAt(i) != '%'){ s.append(q.charAt(i)); }else if(q.charAt(i) == '#'&& s.length()>=1){ s.append(s); }else if(q.charAt(i) == '*' && s.length()>=1){ s.deleteCharAt(s.length()-1); }else{ s.reverse(); } } return s.toString(); }}Dry RunInputs = "abc#%"Step 1aResult:aStep 2bResult:abStep 3cResult:abcStep 4#Duplicate:abcabcStep 5%Reverse:cbacbaFinal Answer:cbacbaWhy StringBuilder Is Better Than StringSuppose we use:result += ch;Every append creates a brand-new string.For large inputs this becomes inefficient.StringBuilder modifies the same object in memory.Benefits:Faster appendFaster deletionBuilt-in reverse operationLower memory overheadThis is why StringBuilder is the preferred interview solution.Complexity AnalysisLet:n = length of input stringTime ComplexityAppendO(1)Delete LastO(1)ReverseO(m)where m is current result length.DuplicateO(m)because the entire string is copied.Overall:O(n × m)In this problem:n ≤ 20so this is perfectly acceptable.Alternative Approach: Using a StackAnother way is storing characters inside a stack.Advantages:Easy handling of *Natural last-in-first-out behaviorDisadvantages:Reversing becomes expensiveDuplicating requires rebuilding dataTherefore, StringBuilder remains the cleaner solution.Interview DiscussionA common interview follow-up is:Why not use String?Because Strings are immutable.Every operation like:result += ch;creates a new object.StringBuilder avoids repeated object creation and is significantly more efficient.Edge CasesCase 1s = "z*#"Process:z → "z"* → ""# → ""Output:""Case 2s = "%"Output:""Reversing an empty string changes nothing.Case 3s = "*"Output:""Nothing exists to delete.Key TakeawaysStringBuilder is ideal for string simulation problems.Process operations strictly from left to right.append(), deleteCharAt(), and reverse() make implementation simple.Always look for mutable string structures when frequent modifications are required.Simulation problems often test implementation accuracy more than algorithmic complexity.ConclusionLeetCode 3612: Process String with Special Operations I is a clean simulation problem that demonstrates how powerful StringBuilder can be for handling dynamic string transformations.By processing each character sequentially and applying the required operation immediately, we can solve the problem efficiently with a straightforward and readable solution.This problem is an excellent exercise for improving string manipulation skills and understanding when to choose mutable data structures over immutable strings.