Stack Data Structure in Java: The Complete In-Depth Guide
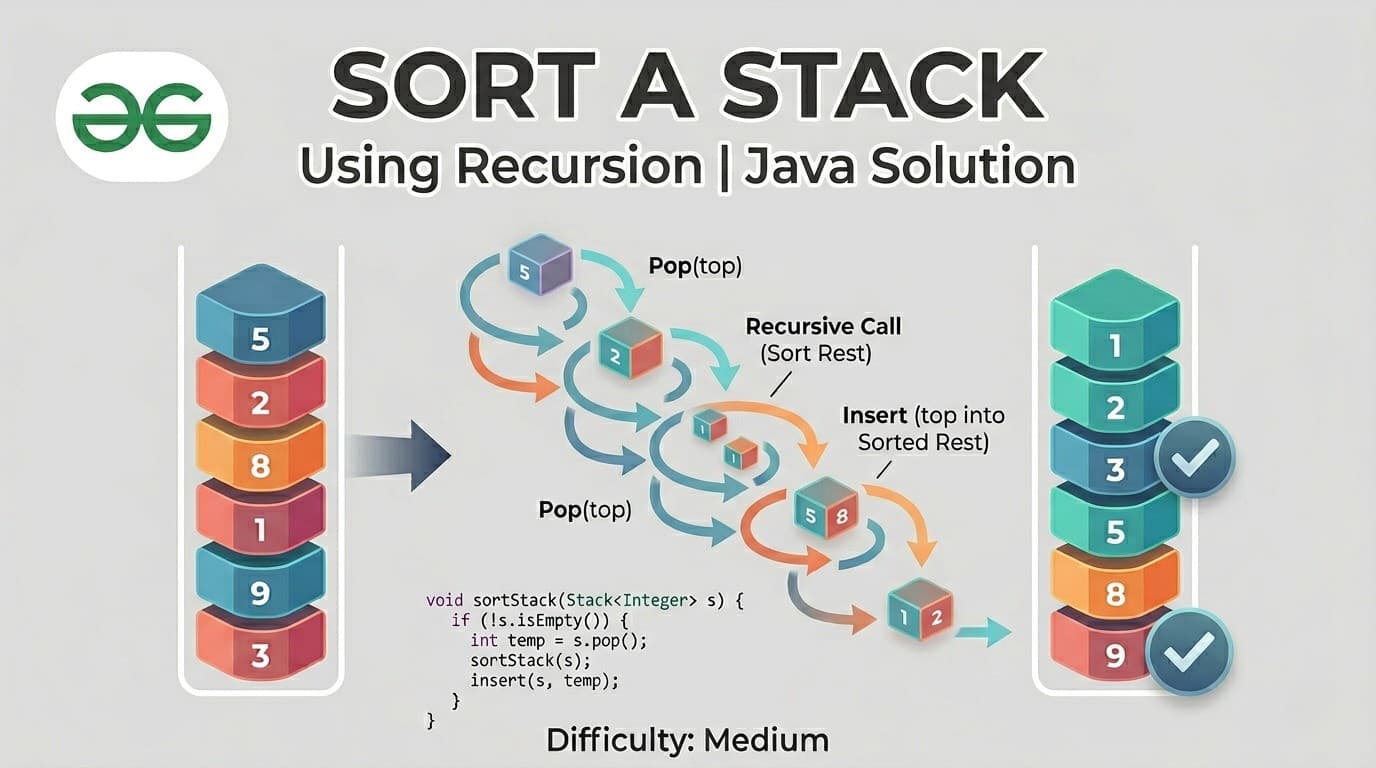
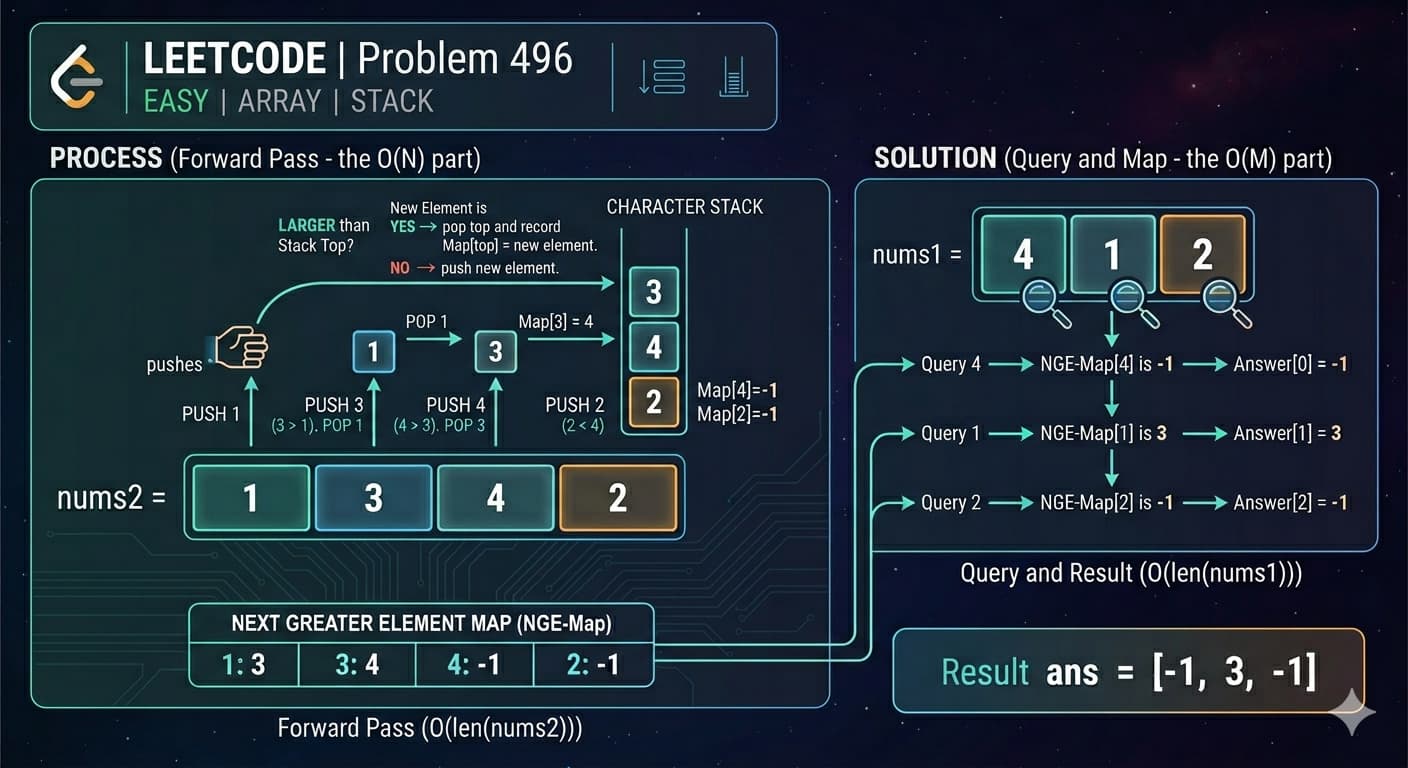
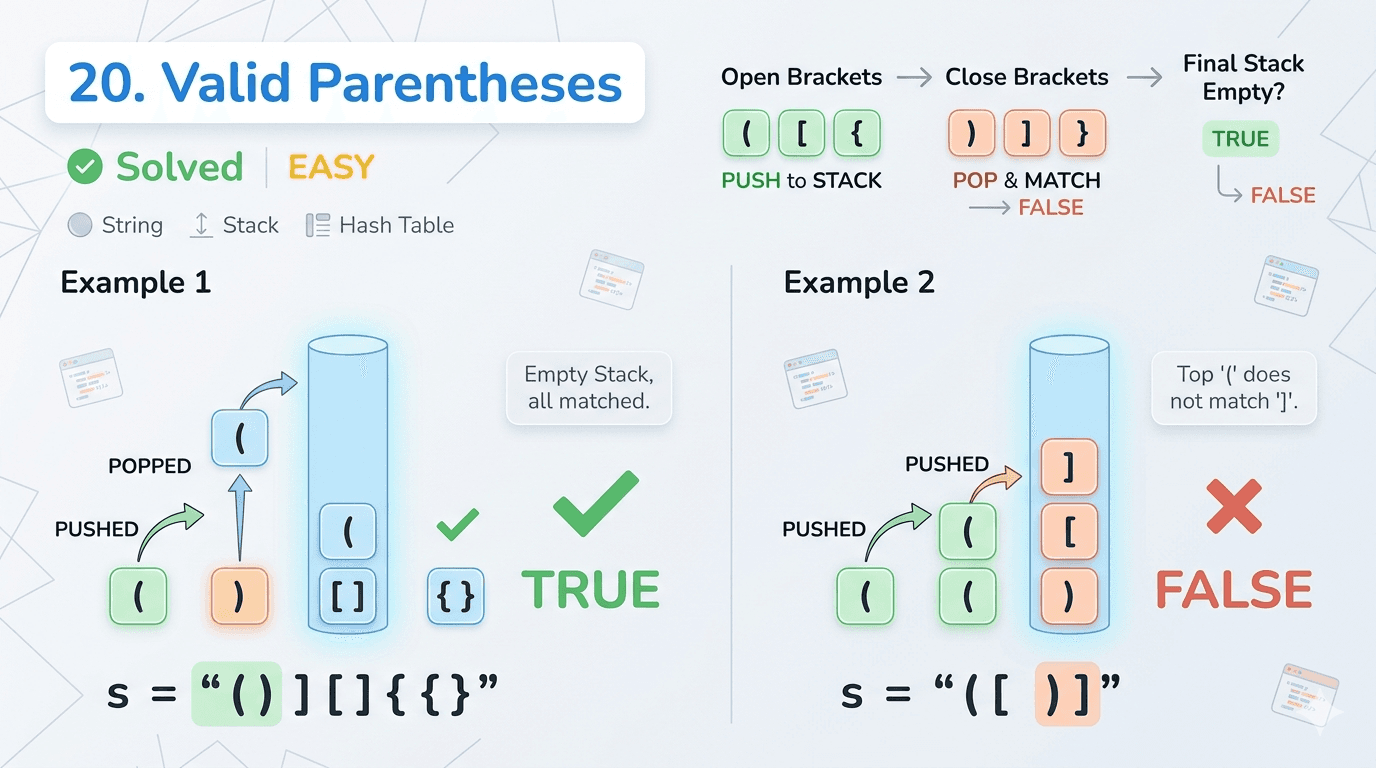
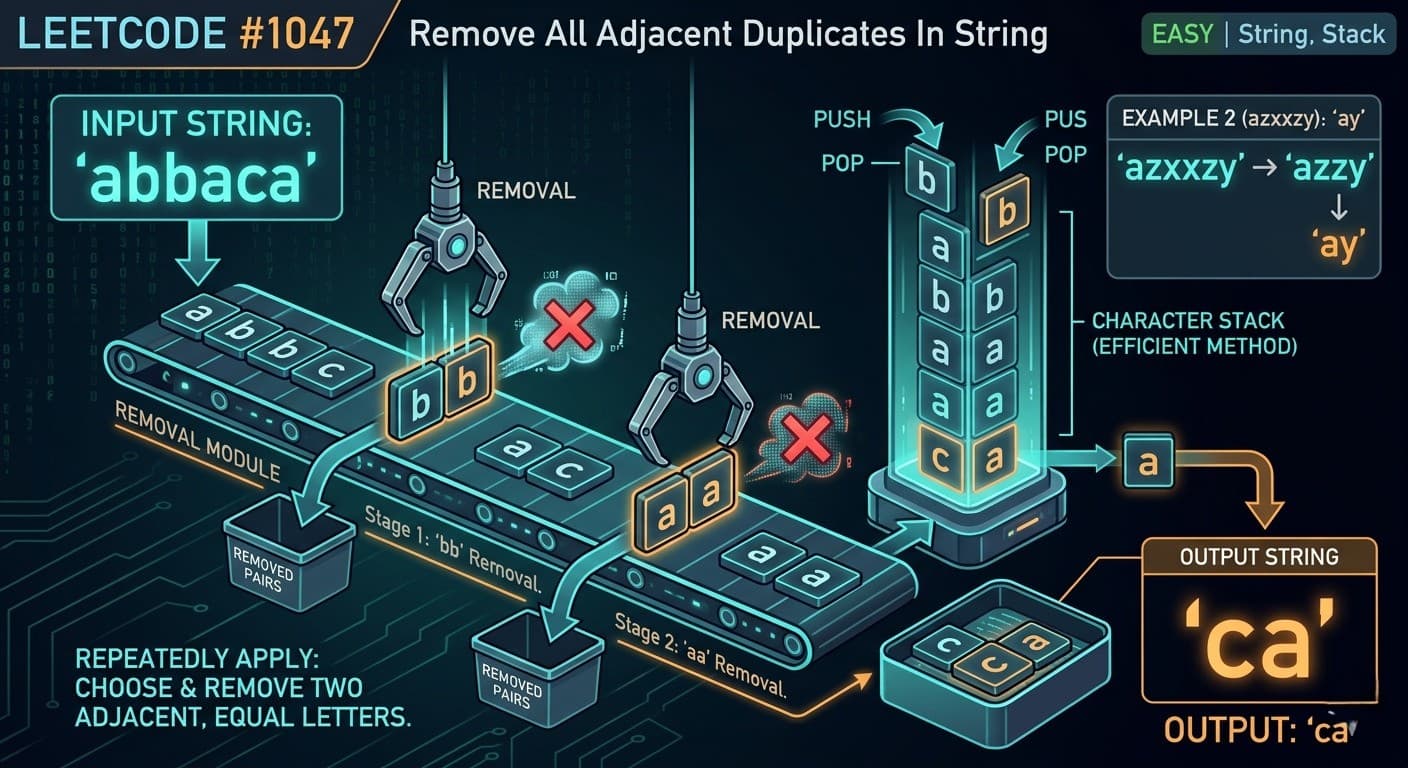
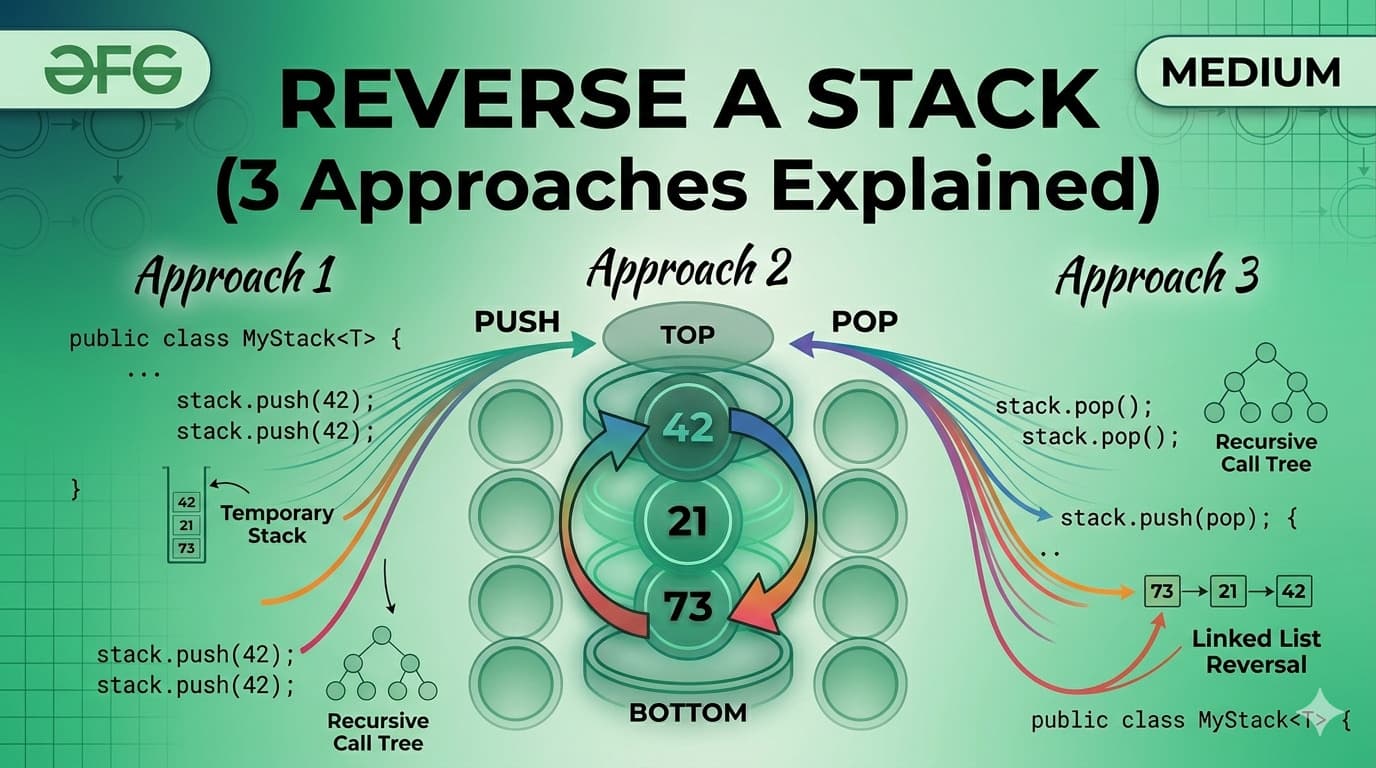
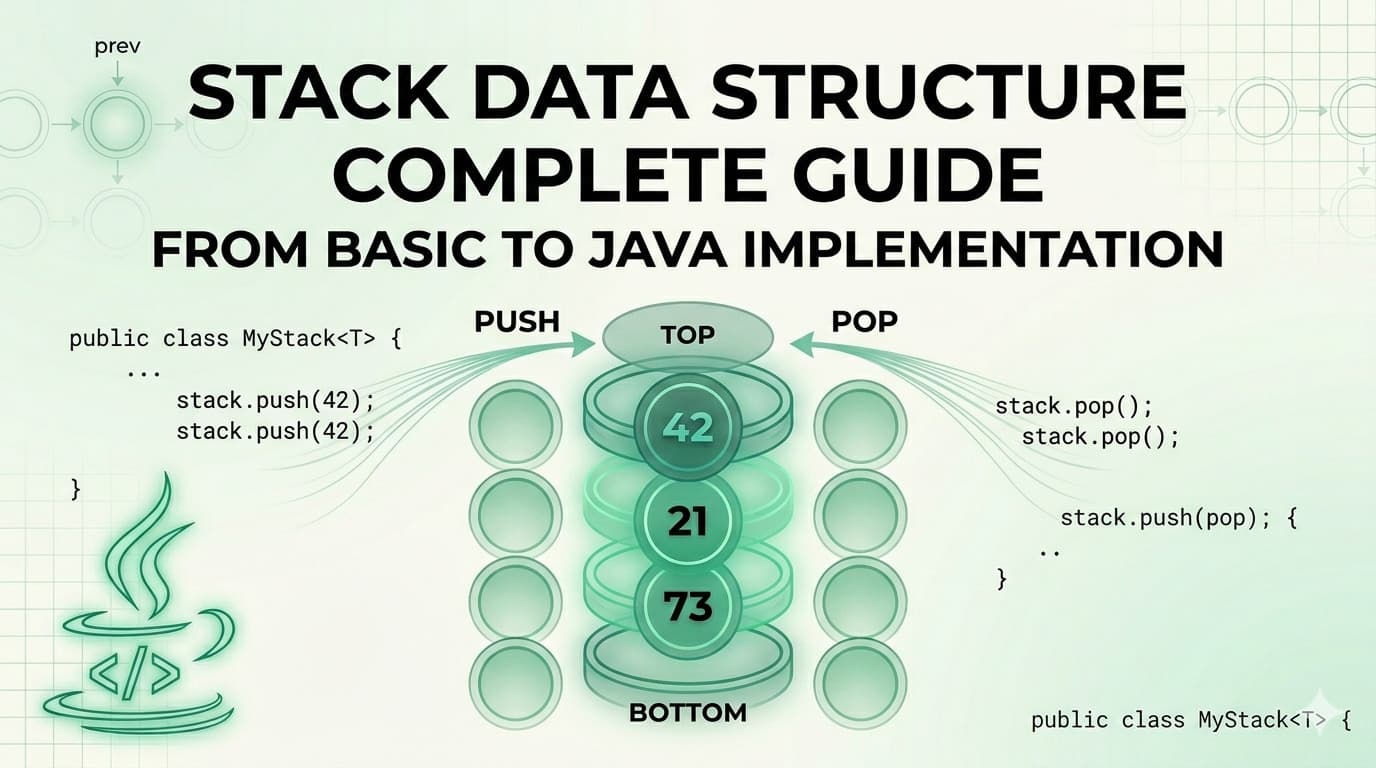
1. What Is a Stack?A Stack is a linear data structure that stores elements in a sequential order, but with one strict rule — you can only insert or remove elements from one end, called the top.It is one of the simplest yet most powerful data structures in computer science. Its strength comes from its constraint. Because everything happens at one end, the behavior of a stack is completely predictable.The formal definition: A Stack is a linear data structure that follows the Last In, First Out (LIFO) principle — the element inserted last is the first one to be removed.Here is what a stack looks like visually: ┌──────────┐ │ 50 │ ← TOP (last inserted, first removed) ├──────────┤ │ 40 │ ├──────────┤ │ 30 │ ├──────────┤ │ 20 │ ├──────────┤ │ 10 │ ← BOTTOM (first inserted, last removed) └──────────┘When you push 60 onto this stack, it goes on top. When you pop, 60 comes out first. That is LIFO.2. Real-World AnalogiesBefore writing a single line of code, it helps to see stacks in the real world. These analogies will make the concept permanently stick.A Pile of Plates In a cafeteria, clean plates are stacked on top of each other. You always pick the top plate. You always place a new plate on top. You never reach into the middle. This is a stack.Browser Back Button Every time you visit a new webpage, it gets pushed onto a history stack. When you press the Back button, the browser pops the most recent page off the stack and takes you there. The page you visited first is at the bottom — you only reach it after going back through everything else.Undo Feature in Text Editors When you type in a document and press Ctrl+Z, the most recent action is undone first. That is because every action you perform is pushed onto a stack. Undo simply pops from that stack.Call Stack in Programming When a function calls another function, the current function's state is pushed onto the call stack. When the inner function finishes, it is popped off and execution returns to the outer function. This is the literal stack your programs run on.A Stack of Books Put five books on a table, one on top of another. You can only take the top book without knocking the pile over. That is a stack.3. The LIFO Principle ExplainedLIFO stands for Last In, First Out.It means whatever you put in last is the first thing to come out. This is the exact opposite of a Queue (which is FIFO — First In, First Out).Let us trace through an example step by step:Start: Stack is empty → []Push 10 → [10] (10 is at the top)Push 20 → [10, 20] (20 is at the top)Push 30 → [10, 20, 30] (30 is at the top)Pop → returns 30 (30 was last in, first out) Stack: [10, 20]Pop → returns 20 Stack: [10]Peek → returns 10 (just looks, does not remove) Stack: [10]Pop → returns 10 Stack: [] (stack is now empty)Every single operation happens only at the top. The bottom of the stack is never directly accessible.4. Stack Operations & Time ComplexityA stack supports the following core operations:OperationDescriptionTime Complexitypush(x)Insert element x onto the top of the stackO(1)pop()Remove and return the top elementO(1)peek() / top()Return the top element without removing itO(1)isEmpty()Check if the stack has no elementsO(1)isFull()Check if the stack has reached its capacity (Array only)O(1)size()Return the number of elements in the stackO(1)search(x)Find position of element from top (Java built-in only)O(n)All primary stack operations — push, pop, peek, isEmpty — run in O(1) constant time. This is what makes the stack so efficient. It does not matter whether the stack has 10 elements or 10 million — these operations are always instant.Space complexity for a stack holding n elements is O(n).5. Implementation 1 — Using a Static ArrayThis is the most fundamental way to implement a stack. We use a fixed-size array and a variable called top to track where the top of the stack currently is.How it works:top starts at -1 (stack is empty)On push: increment top, then place the element at arr[top]On pop: return arr[top], then decrement topOn peek: return arr[top] without changing it// StackUsingArray.javapublic class StackUsingArray { private int[] arr; private int top; private int capacity; // Constructor — initialize with a fixed capacity public StackUsingArray(int capacity) { this.capacity = capacity; arr = new int[capacity]; top = -1; } // Push: add element to the top public void push(int value) { if (isFull()) { System.out.println("Stack Overflow! Cannot push " + value); return; } arr[++top] = value; System.out.println("Pushed: " + value); } // Pop: remove and return top element public int pop() { if (isEmpty()) { System.out.println("Stack Underflow! Stack is empty."); return -1; } return arr[top--]; } // Peek: view the top element without removing public int peek() { if (isEmpty()) { System.out.println("Stack is empty."); return -1; } return arr[top]; } // Check if stack is empty public boolean isEmpty() { return top == -1; } // Check if stack is full public boolean isFull() { return top == capacity - 1; } // Return current size public int size() { return top + 1; } // Display all elements public void display() { if (isEmpty()) { System.out.println("Stack is empty."); return; } System.out.print("Stack (top → bottom): "); for (int i = top; i >= 0; i--) { System.out.print(arr[i] + " "); } System.out.println(); } // Main method to test public static void main(String[] args) { StackUsingArray stack = new StackUsingArray(5); stack.push(10); stack.push(20); stack.push(30); stack.push(40); stack.push(50); stack.push(60); // This will trigger Stack Overflow stack.display(); System.out.println("Peek: " + stack.peek()); System.out.println("Pop: " + stack.pop()); System.out.println("Pop: " + stack.pop()); stack.display(); System.out.println("Size: " + stack.size()); }}```**Output:**```Pushed: 10Pushed: 20Pushed: 30Pushed: 40Pushed: 50Stack Overflow! Cannot push 60Stack (top → bottom): 50 40 30 20 10Peek: 50Pop: 50Pop: 40Stack (top → bottom): 30 20 10Size: 3Key Points about Array Implementation:Fixed size — you must declare capacity upfrontVery fast — direct array index accessStack Overflow is possible if capacity is exceededMemory is pre-allocated even if stack is not full6. Implementation 2 — Using an ArrayListAn ArrayList-based stack removes the fixed-size limitation. The ArrayList grows dynamically, so you never have to worry about stack overflow due to capacity.How it works:The end of the ArrayList acts as the topadd() is used for pushremove(size - 1) is used for popget(size - 1) is used for peek// StackUsingArrayList.javaimport java.util.ArrayList;public class StackUsingArrayList { private ArrayList<Integer> list; // Constructor public StackUsingArrayList() { list = new ArrayList<>(); } // Push: add to the end (which is our top) public void push(int value) { list.add(value); System.out.println("Pushed: " + value); } // Pop: remove and return the last element public int pop() { if (isEmpty()) { System.out.println("Stack Underflow! Stack is empty."); return -1; } int top = list.get(list.size() - 1); list.remove(list.size() - 1); return top; } // Peek: view the last element public int peek() { if (isEmpty()) { System.out.println("Stack is empty."); return -1; } return list.get(list.size() - 1); } // Check if stack is empty public boolean isEmpty() { return list.isEmpty(); } // Return size public int size() { return list.size(); } // Display elements from top to bottom public void display() { if (isEmpty()) { System.out.println("Stack is empty."); return; } System.out.print("Stack (top → bottom): "); for (int i = list.size() - 1; i >= 0; i--) { System.out.print(list.get(i) + " "); } System.out.println(); } // Main method to test public static void main(String[] args) { StackUsingArrayList stack = new StackUsingArrayList(); stack.push(5); stack.push(15); stack.push(25); stack.push(35); stack.display(); System.out.println("Peek: " + stack.peek()); System.out.println("Pop: " + stack.pop()); System.out.println("Pop: " + stack.pop()); stack.display(); System.out.println("Is Empty: " + stack.isEmpty()); System.out.println("Size: " + stack.size()); }}```**Output:**```Pushed: 5Pushed: 15Pushed: 25Pushed: 35Stack (top → bottom): 35 25 15 5Peek: 35Pop: 35Pop: 25Stack (top → bottom): 15 5Is Empty: falseSize: 2Key Points about ArrayList Implementation:Dynamic size — grows automatically as neededNo overflow riskSlight overhead compared to raw array due to ArrayList internalsExcellent for most practical use cases7. Implementation 3 — Using a LinkedListA LinkedList-based stack is the most memory-efficient approach when you do not know the stack size in advance. Each element (node) holds data and a pointer to the next node. The head of the LinkedList acts as the top of the stack.How it works:Each node stores a value and a reference to the node below itPush creates a new node and makes it the new headPop removes the head node and returns its valuePeek returns the head node's value without removing it// StackUsingLinkedList.javapublic class StackUsingLinkedList { // Inner Node class private static class Node { int data; Node next; Node(int data) { this.data = data; this.next = null; } } private Node top; // Head of the linked list = top of stack private int size; // Constructor public StackUsingLinkedList() { top = null; size = 0; } // Push: create new node and link it to top public void push(int value) { Node newNode = new Node(value); newNode.next = top; // new node points to current top top = newNode; // new node becomes the new top size++; System.out.println("Pushed: " + value); } // Pop: remove and return top node's data public int pop() { if (isEmpty()) { System.out.println("Stack Underflow! Stack is empty."); return -1; } int value = top.data; top = top.next; // move top pointer to next node size--; return value; } // Peek: return top node's data without removing public int peek() { if (isEmpty()) { System.out.println("Stack is empty."); return -1; } return top.data; } // Check if empty public boolean isEmpty() { return top == null; } // Return size public int size() { return size; } // Display elements from top to bottom public void display() { if (isEmpty()) { System.out.println("Stack is empty."); return; } System.out.print("Stack (top → bottom): "); Node current = top; while (current != null) { System.out.print(current.data + " "); current = current.next; } System.out.println(); } // Main method to test public static void main(String[] args) { StackUsingLinkedList stack = new StackUsingLinkedList(); stack.push(100); stack.push(200); stack.push(300); stack.push(400); stack.display(); System.out.println("Peek: " + stack.peek()); System.out.println("Pop: " + stack.pop()); System.out.println("Pop: " + stack.pop()); stack.display(); System.out.println("Size: " + stack.size()); }}```**Output:**```Pushed: 100Pushed: 200Pushed: 300Pushed: 400Stack (top → bottom): 400 300 200 100Peek: 400Pop: 400Pop: 300Stack (top → bottom): 200 100Size: 2Key Points about LinkedList Implementation:Truly dynamic — each node allocated only when neededNo wasted memory from pre-allocationSlightly more memory per element (each node carries a pointer)Ideal for stacks where size is completely unknown8. Java's Built-in Stack ClassJava provides a ready-made Stack class inside java.util. It extends Vector and is thread-safe by default.// JavaBuiltinStack.javaimport java.util.Stack;public class JavaBuiltinStack { public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); // Push elements stack.push(10); stack.push(20); stack.push(30); stack.push(40); System.out.println("Stack: " + stack); // Peek — look at top without removing System.out.println("Peek: " + stack.peek()); // Pop — remove top System.out.println("Pop: " + stack.pop()); System.out.println("After pop: " + stack); // Search — returns 1-based position from top System.out.println("Search 20: position " + stack.search(20)); // isEmpty System.out.println("Is Empty: " + stack.isEmpty()); // Size System.out.println("Size: " + stack.size()); }}```**Output:**```Stack: [10, 20, 30, 40]Peek: 40Pop: 40After pop: [10, 20, 30]Search 20: position 2Is Empty: falseSize: 3Important Note: In modern Java development, it is often recommended to use Deque (specifically ArrayDeque) instead of Stack for better performance, since Stack is synchronized and carries the overhead of Vector.// Using ArrayDeque as a stack (modern preferred approach)import java.util.ArrayDeque;import java.util.Deque;public class ModernStack { public static void main(String[] args) { Deque<Integer> stack = new ArrayDeque<>(); stack.push(10); // pushes to front stack.push(20); stack.push(30); System.out.println("Top: " + stack.peek()); System.out.println("Pop: " + stack.pop()); System.out.println("Stack: " + stack); }}9. Comparison of All ImplementationsFeatureArrayArrayListLinkedListJava StackArrayDequeSizeFixedDynamicDynamicDynamicDynamicStack Overflow RiskYesNoNoNoNoMemory UsagePre-allocatedAuto-growsPer-node overheadAuto-growsAuto-growsPush TimeO(1)O(1) amortizedO(1)O(1)O(1)Pop TimeO(1)O(1)O(1)O(1)O(1)Peek TimeO(1)O(1)O(1)O(1)O(1)Thread SafeNoNoNoYesNoBest ForKnown size, max speedGeneral useUnknown/huge sizeLegacy codeModern Java10. Advantages & DisadvantagesAdvantagesAdvantageExplanationSimple to implementVery few rules and operations to worry aboutO(1) operationsPush, pop, and peek are all constant timeMemory efficientNo extra pointers needed (array-based)Supports recursionThe call stack is itself a stackEasy undo/redoNatural fit for reversible action trackingBacktrackingPerfectly suited for maze, puzzle, and game solvingExpression evaluationPowers compilers and calculatorsDisadvantagesDisadvantageExplanationLimited accessCannot access elements in the middle directlyFixed size (array)Array-based stacks overflow if size is exceededNo random accessYou cannot do stack[2] — only top is accessibleMemory waste (array)Pre-allocated array wastes space if underusedNot suitable for all problemsMany problems need queues, trees, or graphs insteadStack overflow in recursionVery deep recursion can overflow the JVM call stack11. Real-World Use Cases of StackUnderstanding when to use a stack is just as important as knowing how to implement one. Here is where stacks show up in real software:Function Call Management (Call Stack) Every time your Java program calls a method, the JVM pushes that method's frame onto the call stack. When the method returns, the frame is popped. This is why you see "StackOverflowError" when you write infinite recursion.Undo and Redo Operations Text editors, image editors (Photoshop), and IDEs use two stacks — one for undo history and one for redo history. Every action pushes onto the undo stack. Ctrl+Z pops from it and pushes to the redo stack.Browser Navigation Your browser maintains a back-stack and a forward-stack. Visiting a new page pushes to the back-stack. Pressing Back pops from it and pushes to the forward-stack.Expression Evaluation and Conversion Compilers use stacks to evaluate arithmetic expressions and convert between infix, prefix, and postfix notations. For example: 3 + 4 * 2 must be evaluated considering operator precedence — this is done with a stack.Balanced Parentheses Checking Linters, compilers, and IDEs use stacks to check if brackets are balanced: {[()]} is valid, {[(])} is not.Backtracking Algorithms Maze solving, N-Queens, Sudoku solvers, and depth-first search all use stacks (explicitly or via recursion) to backtrack to previous states when a path fails.Syntax Parsing Compilers parse source code using stacks to match opening and closing constructs like if/else, try/catch, { and }.12. Practice Problems with Full SolutionsHere is where things get really interesting. These problems will sharpen your stack intuition and prepare you for coding interviews.Problem 1 — Reverse a String Using a StackDifficulty: EasyProblem: Write a Java program to reverse a string using a Stack.Approach: Push every character of the string onto a stack, then pop them all. Since LIFO reverses the order, the characters come out reversed.// ReverseString.javaimport java.util.Stack;public class ReverseString { public static String reverse(String str) { Stack<Character> stack = new Stack<>(); // Push all characters for (char c : str.toCharArray()) { stack.push(c); } // Pop all characters to build reversed string StringBuilder reversed = new StringBuilder(); while (!stack.isEmpty()) { reversed.append(stack.pop()); } return reversed.toString(); } public static void main(String[] args) { System.out.println(reverse("hello")); // olleh System.out.println(reverse("java")); // avaj System.out.println(reverse("racecar")); // racecar (palindrome) System.out.println(reverse("datastructure")); // erutcurtasatad }}Problem 2 — Check Balanced ParenthesesDifficulty: Easy–MediumProblem: Given a string containing (, ), {, }, [, ], determine if the brackets are balanced.Approach: Push every opening bracket onto the stack. When you see a closing bracket, check if it matches the top of the stack. If it does, pop. If it does not, the string is unbalanced.// BalancedParentheses.javaimport java.util.Stack;public class BalancedParentheses { public static boolean isBalanced(String expr) { Stack<Character> stack = new Stack<>(); for (char c : expr.toCharArray()) { // Push all opening brackets if (c == '(' || c == '{' || c == '[') { stack.push(c); } // For closing brackets, check the top of stack else if (c == ')' || c == '}' || c == ']') { if (stack.isEmpty()) return false; char top = stack.pop(); if (c == ')' && top != '(') return false; if (c == '}' && top != '{') return false; if (c == ']' && top != '[') return false; } } // Stack must be empty at the end for a balanced expression return stack.isEmpty(); } public static void main(String[] args) { System.out.println(isBalanced("{[()]}")); // true System.out.println(isBalanced("{[(])}")); // false System.out.println(isBalanced("((()))")); // true System.out.println(isBalanced("{]")); // false System.out.println(isBalanced("")); // true (empty is balanced) }}Problem 3 — Reverse a Stack (Without Extra Data Structure)Difficulty: Medium–HardProblem: Reverse all elements of a stack using only recursion — no array or extra stack allowed.Approach: This is a classic recursion problem. You need two recursive functions:insertAtBottom(stack, item) — inserts an element at the very bottom of the stackreverseStack(stack) — pops all elements, reverses, and uses insertAtBottom to rebuild// ReverseStack.javaimport java.util.Stack;public class ReverseStack { // Insert an element at the bottom of the stack public static void insertAtBottom(Stack<Integer> stack, int item) { if (stack.isEmpty()) { stack.push(item); return; } int top = stack.pop(); insertAtBottom(stack, item); stack.push(top); } // Reverse the stack using insertAtBottom public static void reverseStack(Stack<Integer> stack) { if (stack.isEmpty()) return; int top = stack.pop(); reverseStack(stack); // reverse the remaining stack insertAtBottom(stack, top); // insert popped element at bottom } public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); stack.push(1); stack.push(2); stack.push(3); stack.push(4); stack.push(5); System.out.println("Before: " + stack); // [1, 2, 3, 4, 5] reverseStack(stack); System.out.println("After: " + stack); // [5, 4, 3, 2, 1] }}Problem 4 — Evaluate a Postfix ExpressionDifficulty: MediumProblem: Evaluate a postfix (Reverse Polish Notation) expression. Example: "2 3 4 * +" should return 14 because it is 2 + (3 * 4).Approach: Scan left to right. If you see a number, push it. If you see an operator, pop two numbers, apply the operator, and push the result.// PostfixEvaluation.javaimport java.util.Stack;public class PostfixEvaluation { public static int evaluate(String expression) { Stack<Integer> stack = new Stack<>(); String[] tokens = expression.split(" "); for (String token : tokens) { // If it's a number, push it if (token.matches("-?\\d+")) { stack.push(Integer.parseInt(token)); } // If it's an operator, pop two and apply else { int b = stack.pop(); // second operand int a = stack.pop(); // first operand switch (token) { case "+": stack.push(a + b); break; case "-": stack.push(a - b); break; case "*": stack.push(a * b); break; case "/": stack.push(a / b); break; } } } return stack.pop(); } public static void main(String[] args) { System.out.println(evaluate("2 3 4 * +")); // 14 → 2 + (3*4) System.out.println(evaluate("5 1 2 + 4 * + 3 -")); // 14 → 5+((1+2)*4)-3 System.out.println(evaluate("3 4 +")); // 7 }}Problem 5 — Next Greater ElementDifficulty: MediumProblem: For each element in an array, find the next greater element to its right. If none exists, output -1.Example: Input: [4, 5, 2, 10, 8] → Output: [5, 10, 10, -1, -1]Approach: Iterate right to left. Maintain a stack of candidates. For each element, pop all stack elements that are smaller than or equal to it — they can never be the answer for any element to the left. The top of the stack (if not empty) is the next greater element.// NextGreaterElement.javaimport java.util.Stack;import java.util.Arrays;public class NextGreaterElement { public static int[] nextGreater(int[] arr) { int n = arr.length; int[] result = new int[n]; Stack<Integer> stack = new Stack<>(); // stores elements, not indices // Traverse from right to left for (int i = n - 1; i >= 0; i--) { // Pop elements smaller than or equal to current while (!stack.isEmpty() && stack.peek() <= arr[i]) { stack.pop(); } // Next greater element result[i] = stack.isEmpty() ? -1 : stack.peek(); // Push current element for future comparisons stack.push(arr[i]); } return result; } public static void main(String[] args) { int[] arr1 = {4, 5, 2, 10, 8}; System.out.println(Arrays.toString(nextGreater(arr1))); // [5, 10, 10, -1, -1] int[] arr2 = {1, 3, 2, 4}; System.out.println(Arrays.toString(nextGreater(arr2))); // [3, 4, 4, -1] int[] arr3 = {5, 4, 3, 2, 1}; System.out.println(Arrays.toString(nextGreater(arr3))); // [-1, -1, -1, -1, -1] }}Problem 6 — Sort a Stack Using RecursionDifficulty: HardProblem: Sort a stack in ascending order (smallest on top) using only recursion — no loops, no extra data structure.// SortStack.javaimport java.util.Stack;public class SortStack { // Insert element in correct sorted position public static void sortedInsert(Stack<Integer> stack, int item) { if (stack.isEmpty() || item > stack.peek()) { stack.push(item); return; } int top = stack.pop(); sortedInsert(stack, item); stack.push(top); } // Sort the stack public static void sortStack(Stack<Integer> stack) { if (stack.isEmpty()) return; int top = stack.pop(); sortStack(stack); // sort remaining sortedInsert(stack, top); // insert top in sorted position } public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); stack.push(34); stack.push(3); stack.push(31); stack.push(98); stack.push(92); stack.push(23); System.out.println("Before sort: " + stack); sortStack(stack); System.out.println("After sort: " + stack); // smallest on top }}13. Summary & Key TakeawaysA stack is a simple, elegant, and powerful data structure. Here is everything in one place:What it is: A linear data structure that follows LIFO — Last In, First Out.Core operations: push (add to top), pop (remove from top), peek (view top), isEmpty — all in O(1) time.Three ways to implement it in Java:Array-based: fast, fixed size, risk of overflowArrayList-based: dynamic, easy, slightly more overheadLinkedList-based: truly dynamic, memory-efficient per-element, best for unknown sizesWhen to use it:Undo/redo systemsBrowser navigationBalancing brackets and parenthesesEvaluating mathematical expressionsBacktracking problemsManaging recursive function callsDepth-first searchWhen NOT to use it:When you need random access to elementsWhen insertion/deletion is needed from both ends (use Deque)When you need to search efficiently (use HashMap or BST)Modern Java recommendation: Prefer ArrayDeque over the legacy Stack class for non-thread-safe scenarios. Use Stack only when you need synchronized access.The stack is one of those data structures that once you truly understand, you start seeing it everywhere — in your browser, in your IDE, in recursive algorithms, and deep within the operating system itself.This article covered everything from the fundamentals of the Stack data structure to multiple Java implementations, time complexity analysis, real-world applications, and six practice problems of increasing difficulty. Bookmark it as a reference and revisit the practice problems regularly — they are the real test of your understanding.