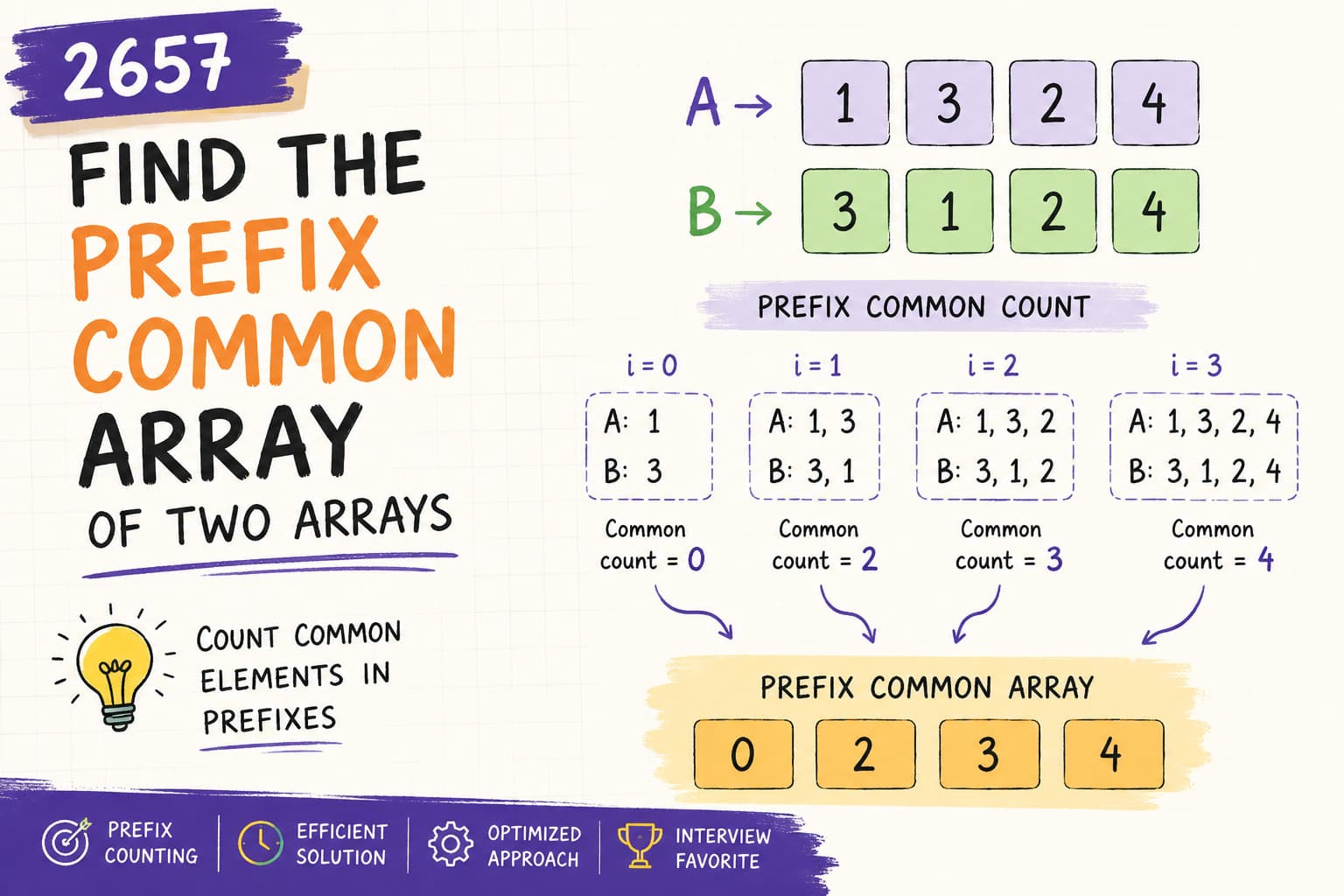
LeetCode 1752: Check if Array Is Sorted and Rotated – Java Solution Explained
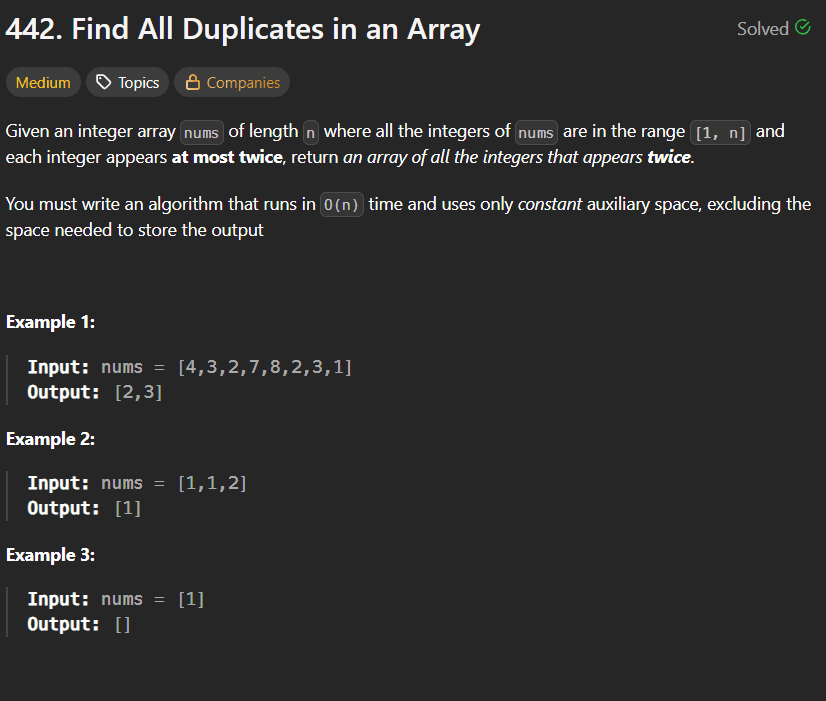
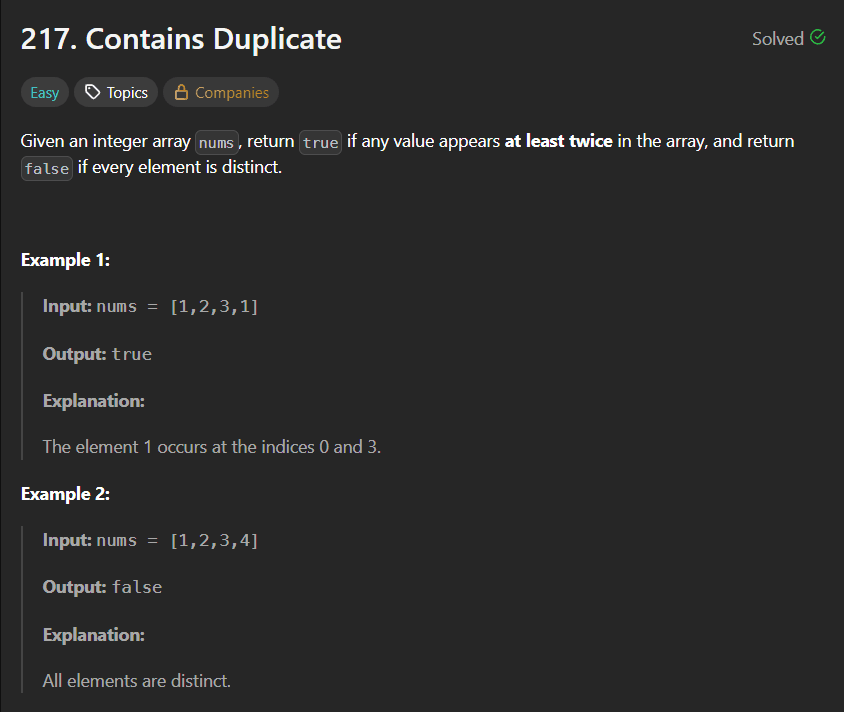
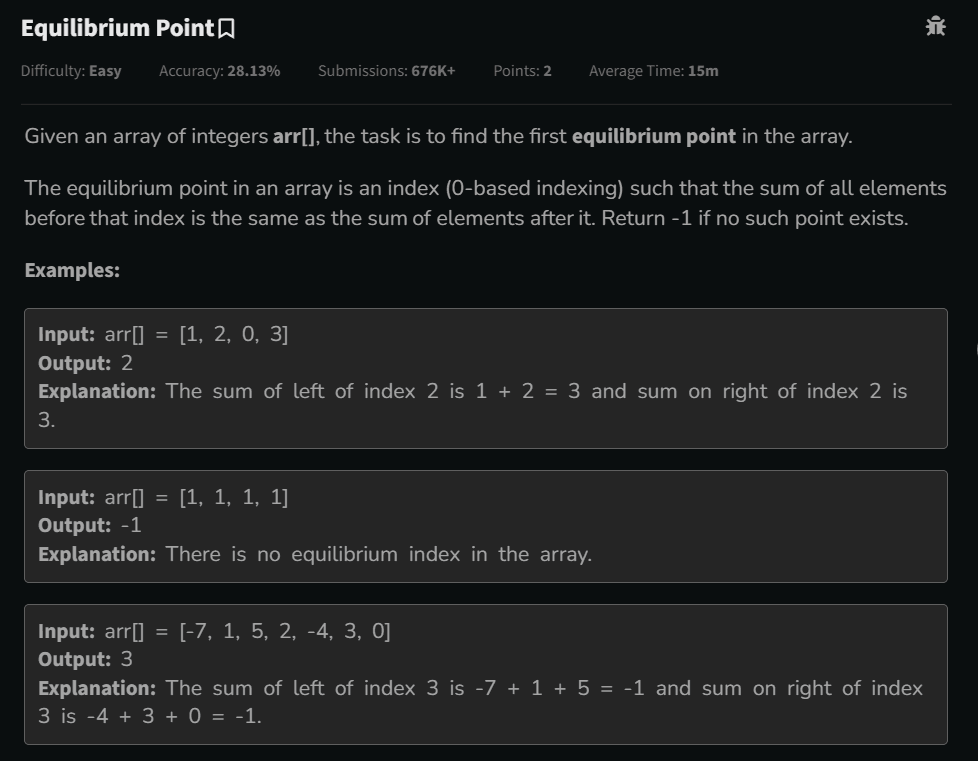
IntroductionLeetCode 1752 – Check if Array Is Sorted and Rotated is a classic array observation problem that tests your understanding of:Sorted arraysRotation logicCircular traversalEdge case handlingPattern recognitionAt first, many developers overcomplicate this problem by trying to actually rotate arrays and compare them. However, the problem can be solved using a very elegant observation.This problem is commonly asked in coding interviews because it evaluates:Logical thinkingArray traversal skillsOptimization abilityUnderstanding of rotated arraysProblem Link🔗 https://leetcode.com/problems/check-if-array-is-sorted-and-rotated/Problem StatementGiven an array:numsReturn:trueif the array was originally sorted in non-decreasing order and then rotated some number of times.Otherwise return:falseDuplicates are allowed.Understanding RotationSuppose the original sorted array is:[1,2,3,4,5]After rotation:[3,4,5,1,2]The array is still almost sorted except for one “breaking point”.Key ObservationA sorted rotated array can have:At most one decreasing pairExample:[3,4,5,1,2]Breaking point:5 > 1Only once.Invalid Example[2,1,3,4]Breaking points:2 > 1and circularly:4 > 2Two breaking points.So answer is:falseBrute Force ApproachIntuitionTry all possible rotations.For every rotation:Rotate arrayCheck if sortedIf any rotation works → return trueBrute Force AlgorithmFor every rotation count:Create rotated arrayVerify sorted orderIf sorted:return trueElse:return falseBrute Force ComplexityTime ComplexityO(N²)because each rotation requires traversal.Space ComplexityO(N)This solution:Finds rotation pointSorts arrayRotates sorted arrayCompares with originalThis is a valid simulation-based approach.Java Solutionclass Solution { public boolean check(int[] nums) { int[] arr = new int[nums.length]; int o = 0; int mini = Integer.MIN_VALUE; int temp = 0; int maxnumind = 0; for(int a : nums) { arr[o] = a; temp = mini; mini = Math.max(mini, a); if(mini != temp) { maxnumind = o; } o++; } for(int i = 0; i < nums.length - 1; i++) { if(nums[i] > nums[i + 1]) { maxnumind = i; } } int ro = nums.length - maxnumind - 1; Arrays.sort(nums); int[] rotarr = new int[nums.length]; for(int i = 0; i < nums.length; i++) { rotarr[i] = nums[(i + ro) % nums.length]; } for(int i = 0; i < arr.length; i++) { if(rotarr[i] != arr[i]) { return false; } } return true; }}Optimized Approach (Best Solution)We do not need:SortingExtra arraysRotation simulationWe only count:decreasing pairsOptimized IntuitionFor a valid rotated sorted array:nums[i] > nums[i+1]can happen only once.Also check circular condition:last element > first elementOptimized Java Solutionclass Solution { public boolean check(int[] nums) { int count = 0; for(int i = 0; i < nums.length; i++) { if(nums[i] > nums[(i + 1) % nums.length]) { count++; } } return count <= 1; }}Why This WorksIf array is sorted and rotated:Sequence increases normallyOnly one position breaks orderIf more than one break exists:Not a rotated sorted arrayDry RunInputnums = [3,4,5,1,2]Step 1Compare adjacent elements:3 < 44 < 55 > 1 ← breaking point1 < 22 < 3 (circular)Breaking points:1Valid.Return:trueAnother Dry RunInputnums = [2,1,3,4]Comparisons:2 > 1 ← break1 < 33 < 44 > 2 ← circular breakBreaking points:2Invalid.Return:falseTime Complexity AnalysisTime ComplexityO(N log N)because of sorting.Space ComplexityO(N)extra arrays used.Optimized ApproachTime ComplexityO(N)single traversal.Space ComplexityO(1)Comparison of ApproachesApproachTime ComplexitySpace ComplexityRotation SimulationO(N log N)O(N)Decreasing Pair CountO(N)O(1)Interview ExplanationIn interviews, explain:A sorted rotated array can contain only one position where the order decreases. By counting such breaking points including circular comparison, we can determine validity in linear time.This demonstrates:Pattern recognitionCircular traversal understandingOptimization thinkingCommon Mistakes1. Forgetting Circular CheckAlways compare:nums[n-1] > nums[0]using modulo.2. Actually Rotating ArraysUnnecessary and inefficient.3. Using Strictly Increasing LogicDuplicates are allowed.So:1,1,2,2is valid.FAQsQ1. Why use modulo?To compare:last element with first elementcircularly.Q2. Why is only one break allowed?Because rotation shifts sorted order only once.Q3. Is sorting required?No.Observation-based traversal is enough.Q4. Is this problem important for interviews?Yes.It tests:Array logicRotationsOptimizationObservation skillsRelated ProblemsAfter mastering this problem, practice:Search in Rotated Sorted ArrayFind Minimum in Rotated Sorted ArrayFind Minimum in Rotated Sorted Array IIConclusionLeetCode 1752 is an excellent observation-based array problem.It teaches:Rotated array logicCircular traversalOptimization techniquesPattern recognitionThe key insight is:A sorted rotated array can have at most one decreasing point.Once you understand this observation, the optimized solution becomes extremely clean and efficient.