LeetCode 290: Word Pattern – Multiple Ways to Verify Bijection Between Pattern Characters and Words
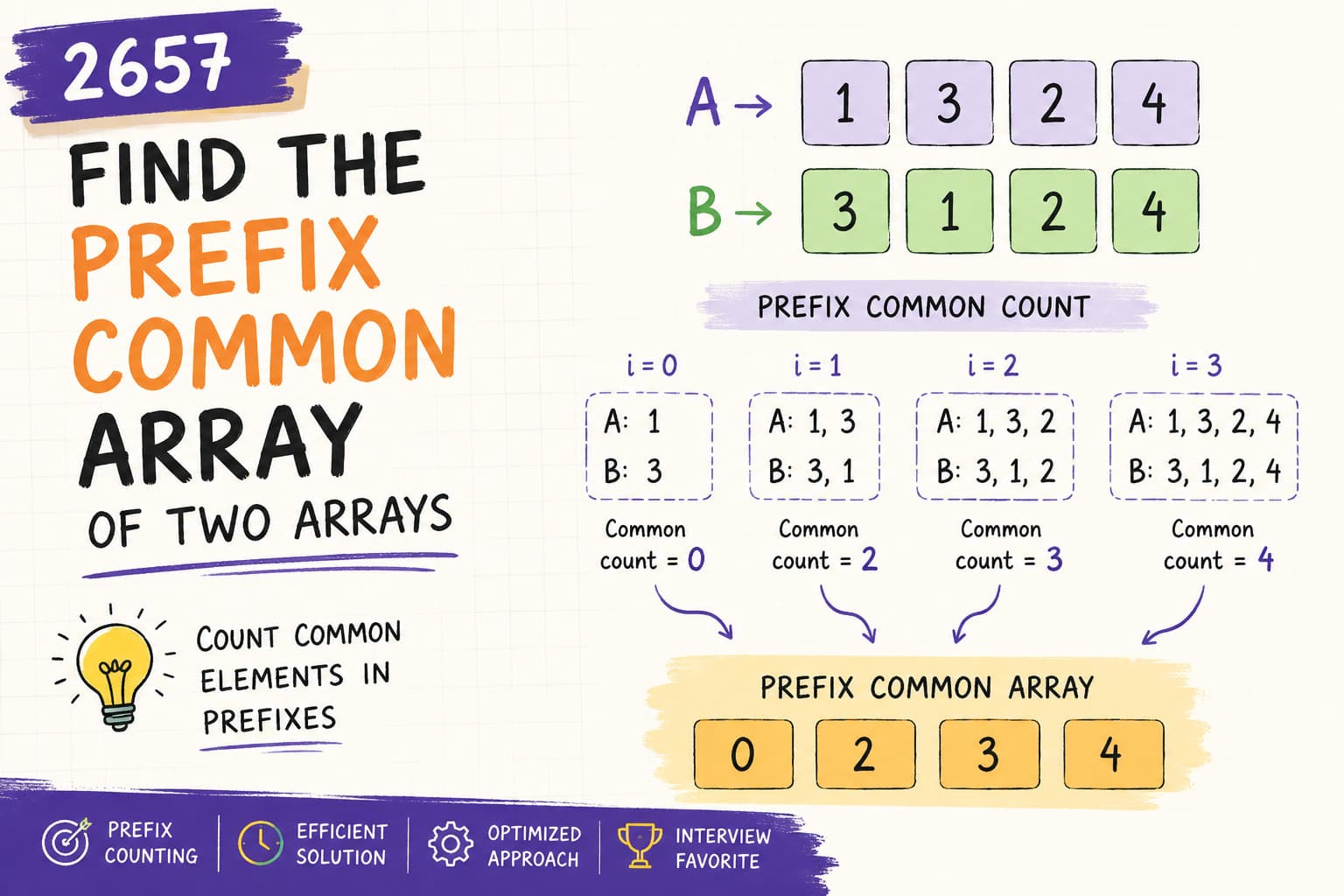
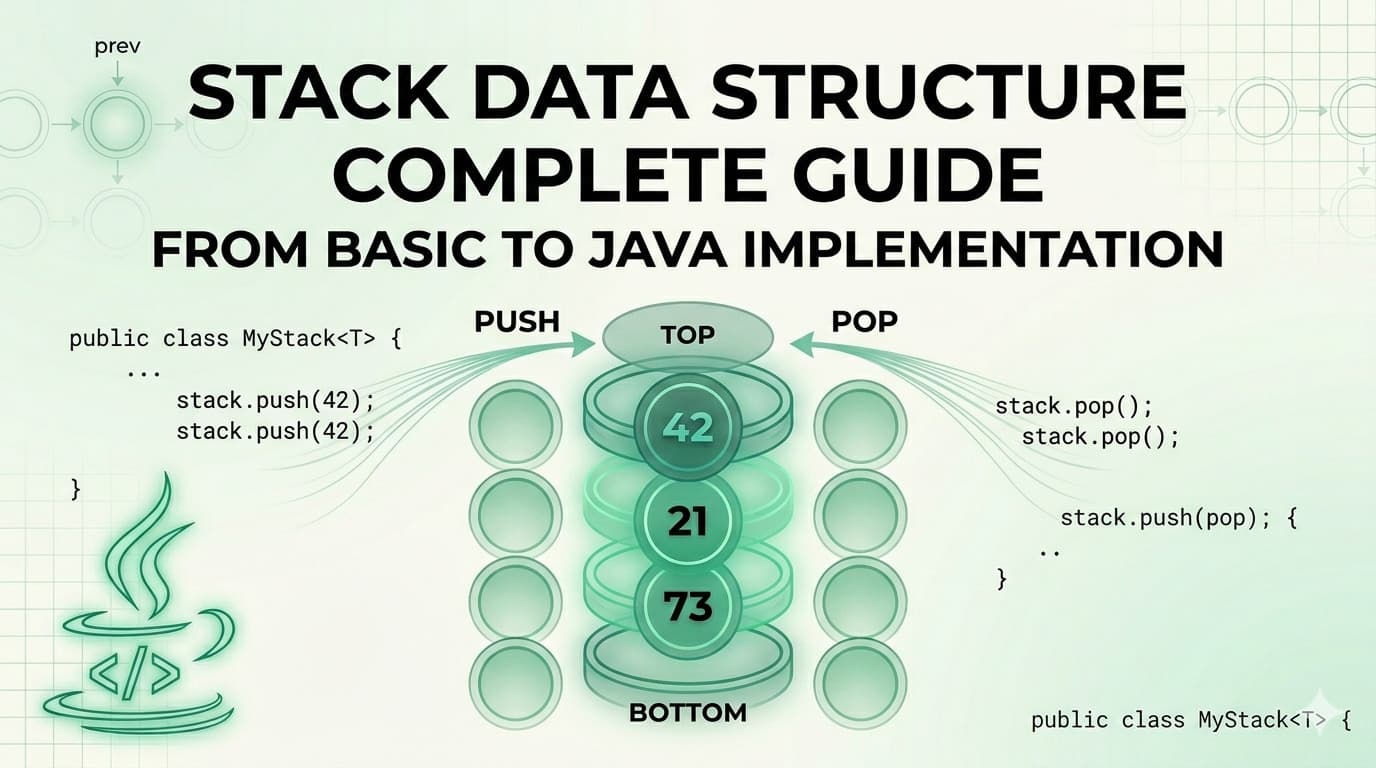
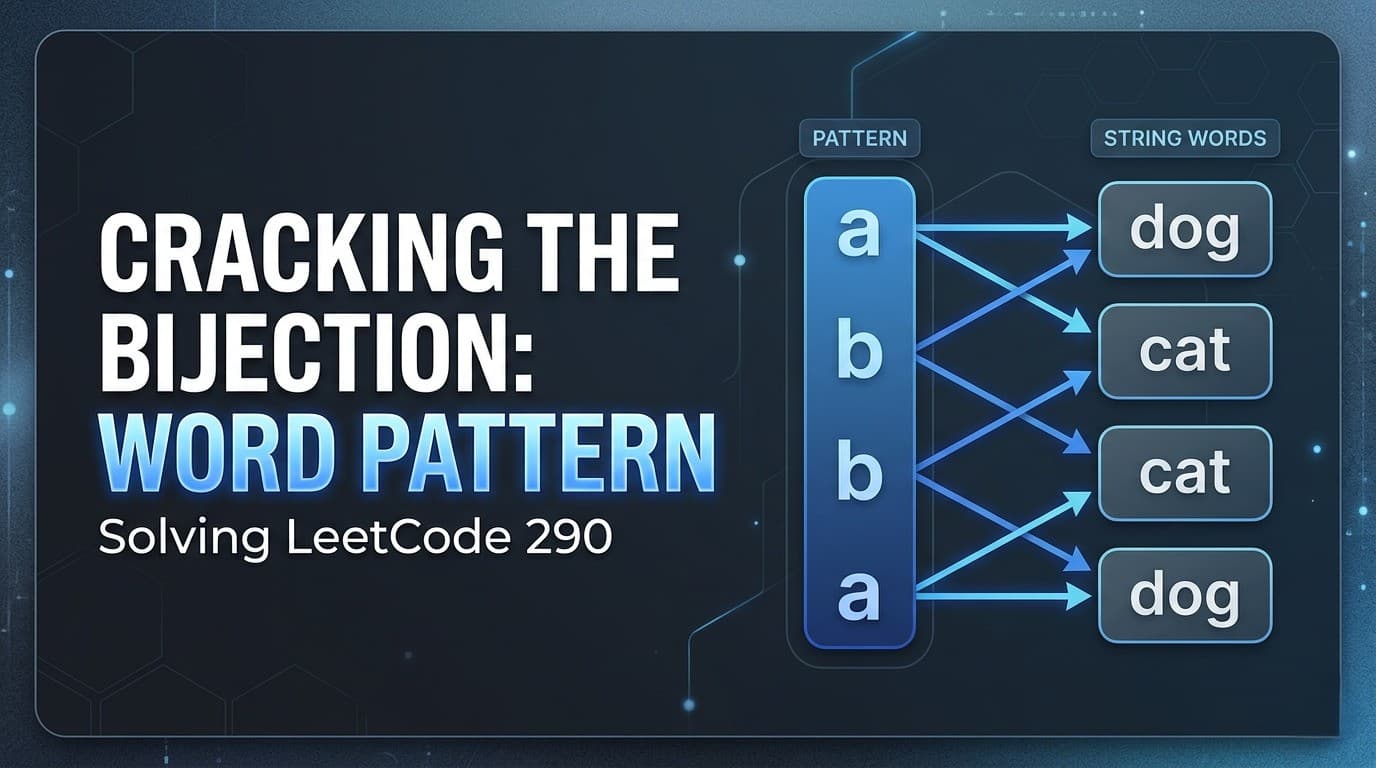
Try the ProblemYou can practice the problem here:https://leetcode.com/problems/word-pattern/Problem DescriptionYou are given:A string patternA string sThe string s consists of words separated by spaces.Your task is to determine whether s follows the same pattern defined by the string pattern.To follow the pattern, there must be a bijection between pattern characters and words.Understanding the Meaning of BijectionA bijection means a one-to-one relationship between two sets.For this problem it means:Every character in the pattern maps to exactly one word.Every word maps to exactly one pattern character.Two characters cannot map to the same word.Two words cannot map to the same character.This ensures the mapping is unique in both directions.Example WalkthroughExample 1Inputpattern = "abba"s = "dog cat cat dog"OutputtrueExplanationMapping:a → dogb → catPattern:a b b aWords:dog cat cat dogThe mapping is perfectly consistent.Example 2Inputpattern = "abba"s = "dog cat cat fish"OutputfalseExplanationThe last word "fish" breaks the pattern because "a" was already mapped to "dog".Example 3Inputpattern = "aaaa"s = "dog cat cat dog"OutputfalseExplanationPattern requires:a → same word every timeBut the words differ.Constraints1 <= pattern.length <= 300pattern contains lowercase English letters1 <= s.length <= 3000s contains lowercase letters and spaceswords are separated by a single spaceno leading or trailing spacesCore ObservationBefore applying any algorithm, we should verify one simple condition.If the number of pattern characters does not match the number of words, then the pattern cannot match.Example:pattern = "abba"s = "dog cat dog"Pattern length = 4Words = 3This automatically returns false.Thinking About Possible ApproachesWhile solving this problem, several strategies may come to mind:Use one HashMap to store pattern → word mapping and check duplicates manually.Use two HashMaps to enforce bijection from both directions.Track first occurrence indices of pattern characters and words.Compare mapping patterns using arrays or maps.Let’s explore these approaches one by one.Approach 1: Single HashMap (Your Solution)IdeaWe store mapping:pattern character → wordWhile iterating:If the character already exists in the map→ check if it maps to the same word.If it does not exist→ ensure that no other character already maps to that word.This ensures bijection.Java Implementationclass Solution { public boolean wordPattern(String pattern, String s) { String words[] = s.split(" "); // Length mismatch means impossible mapping if(pattern.length() != words.length) return false; HashMap<Character,String> mp = new HashMap<>(); for(int i = 0; i < words.length; i++){ char ch = pattern.charAt(i); if(mp.containsKey(ch)){ if(!mp.get(ch).equals(words[i])){ return false; } }else{ // Prevent two characters mapping to same word if(mp.containsValue(words[i])){ return false; } } mp.put(ch, words[i]); } return true; }}Time ComplexityO(n²)Because containsValue() can take O(n) time in worst case.Space ComplexityO(n)Approach 2: Two HashMaps (Cleaner Bijection Enforcement)IdeaInstead of checking containsValue, we maintain two maps.pattern → wordword → patternThis ensures bijection naturally.Java Implementationclass Solution { public boolean wordPattern(String pattern, String s) { String[] words = s.split(" "); if(pattern.length() != words.length) return false; HashMap<Character, String> map1 = new HashMap<>(); HashMap<String, Character> map2 = new HashMap<>(); for(int i = 0; i < pattern.length(); i++){ char ch = pattern.charAt(i); String word = words[i]; if(map1.containsKey(ch) && !map1.get(ch).equals(word)) return false; if(map2.containsKey(word) && map2.get(word) != ch) return false; map1.put(ch, word); map2.put(word, ch); } return true; }}Time ComplexityO(n)Because both maps allow constant-time lookups.Space ComplexityO(n)Approach 3: Index Mapping Technique (Elegant Trick)IdeaAnother clever technique is to compare first occurrence indices.Example:pattern = abbawords = dog cat cat dogPattern index sequence:a → 0b → 1b → 1a → 0Words index sequence:dog → 0cat → 1cat → 1dog → 0If the index sequences match, then the pattern holds.Java Implementationclass Solution { public boolean wordPattern(String pattern, String s) { String[] words = s.split(" "); if(pattern.length() != words.length) return false; HashMap<Character,Integer> map1 = new HashMap<>(); HashMap<String,Integer> map2 = new HashMap<>(); for(int i = 0; i < pattern.length(); i++){ char ch = pattern.charAt(i); String word = words[i]; if(!map1.getOrDefault(ch, -1) .equals(map2.getOrDefault(word, -1))){ return false; } map1.put(ch, i); map2.put(word, i); } return true; }}Time ComplexityO(n)Space ComplexityO(n)Comparison of ApproachesApproachTime ComplexitySpace ComplexityNotesSingle HashMapO(n²)O(n)Simple but slowerTwo HashMapsO(n)O(n)Cleaner bijection enforcementIndex MappingO(n)O(n)Elegant and interview-friendlyKey Interview InsightProblems like this test your understanding of:Bijection MappingSimilar problems include:Isomorphic StringsWord Pattern IISubstitution Cipher ProblemsUnderstanding how to enforce one-to-one mappings is a powerful technique.ConclusionThe Word Pattern problem is an excellent example of how HashMaps can enforce relationships between two datasets.While a simple HashMap solution works, more optimized methods like two-way mapping or index comparison provide cleaner and more efficient implementations.Mastering these techniques will help you solve many pattern-matching and mapping problems commonly asked in coding interviews.