LeetCode 145: Binary Tree Postorder Traversal – Java Recursive & Iterative Solution Explained
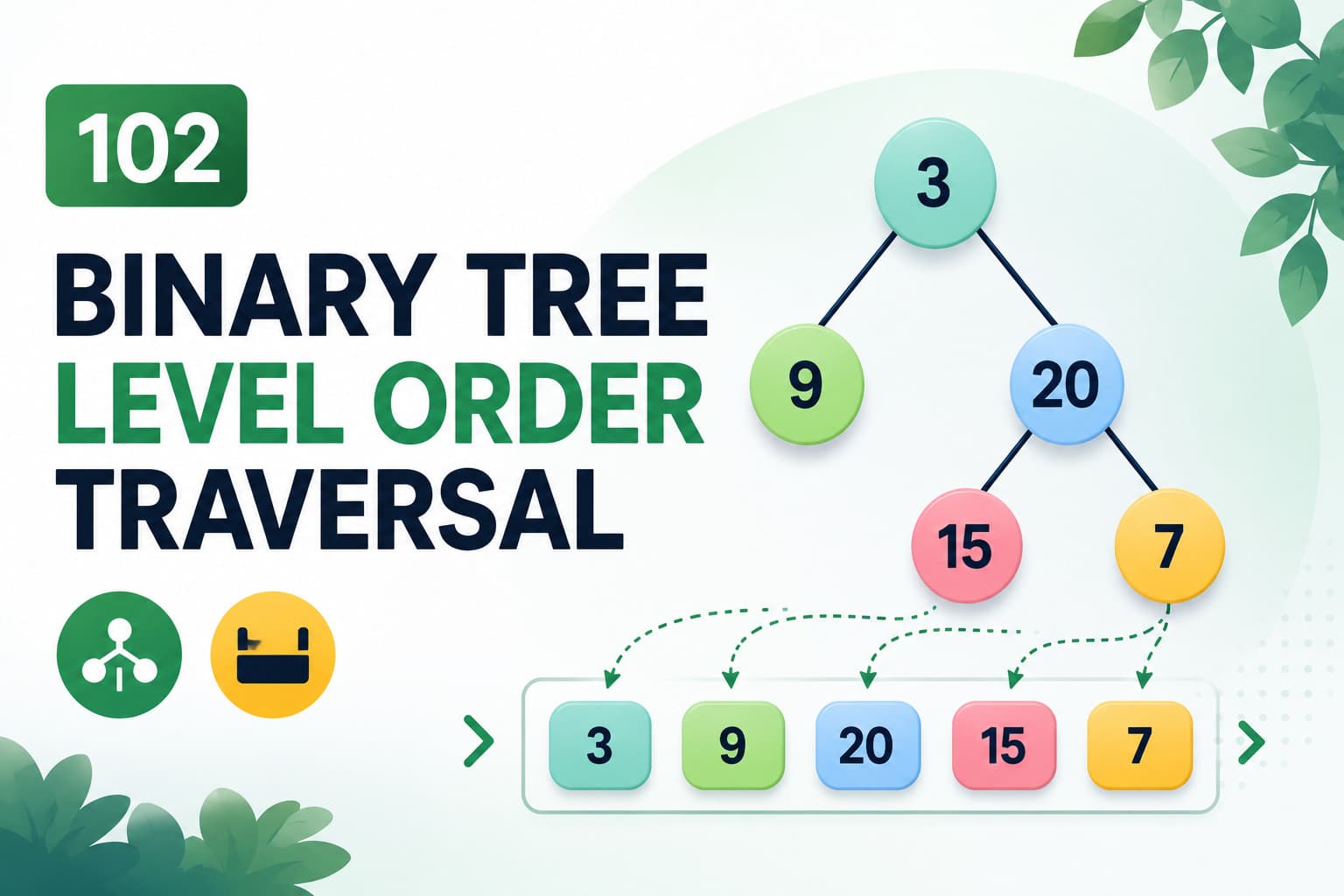
IntroductionLeetCode 145 – Binary Tree Postorder Traversal is one of the most important tree traversal problems for beginners learning Data Structures and Algorithms.This problem teaches:Binary Tree TraversalDepth First Search (DFS)RecursionStack-based traversalTree traversal patternsPostorder traversal is extremely useful in advanced tree problems such as:Tree deletionExpression tree evaluationBottom-up computationsDynamic programming on treesProblem Link🔗 https://leetcode.com/problems/binary-tree-postorder-traversal/Problem StatementGiven the root of a binary tree, return the postorder traversal of its nodes' values.What is Postorder Traversal?In postorder traversal, nodes are visited in this order:Left → Right → RootUnlike preorder or inorder traversal, the root node is processed at the end.ExampleInputroot = [1,null,2,3]Tree Structure:1\2/3Postorder TraversalTraversal order:3 → 2 → 1Output:[3,2,1]Recursive Approach (Most Common)IntuitionIn postorder traversal:Traverse left subtreeTraverse right subtreeVisit current nodeThis naturally fits recursion because trees themselves are recursive structures.Recursive DFS VisualizationTraversal pattern:Left → Right → RootRecursive function:postorder(node.left)postorder(node.right)visit(node)Java Recursive Solution/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* }*/class Solution {public void solve(List<Integer> list, TreeNode root) {if(root == null) return;solve(list, root.left);solve(list, root.right);list.add(root.val);}public List<Integer> postorderTraversal(TreeNode root) {List<Integer> list = new ArrayList<>();solve(list, root);return list;}}Dry Run – Recursive ApproachTree:1\2/3Step 1Start at:1Move left:nullReturn back.Step 2Move right to:2Move left to:3Left and right of 3 are null.Add:3Step 3Return to:2Add:2Step 4Return to:1Add:1Final Answer[3,2,1]Time Complexity – RecursiveTime ComplexityO(N)Every node is visited once.Space ComplexityO(H)Where:H = height of the treeRecursive call stack uses extra spaceWorst case:O(N)for skewed trees.Iterative Approach (Interview Follow-Up)The follow-up asks:Can you solve it iteratively?Yes.We use stacks to simulate recursion.Iterative Postorder IntuitionPostorder traversal order is:Left → Right → RootOne common trick is:Traverse in modified preorder:Root → Right → LeftReverse the result.After reversing, we get:Left → Right → Rootwhich is postorder traversal.Stack-Based Iterative LogicAlgorithmPush root into stack.Pop node.Add node value to answer.Push left child.Push right child.Reverse final answer.Java Iterative Solutionclass Solution {public List<Integer> postorderTraversal(TreeNode root) {LinkedList<Integer> ans = new LinkedList<>();if(root == null) return ans;Stack<TreeNode> stack = new Stack<>();stack.push(root);while(!stack.isEmpty()) {TreeNode node = stack.pop();ans.addFirst(node.val);if(node.left != null) {stack.push(node.left);}if(node.right != null) {stack.push(node.right);}}return ans;}}Dry Run – Iterative ApproachTree:1\2/3Step 1Push:1Step 2Pop:1Add at front:[1]Push right child:2Step 3Pop:2Add at front:[2,1]Push left child:3Step 4Pop:3Add at front:[3,2,1]Final Answer[3,2,1]Comparison of ApproachesApproachAdvantagesDisadvantagesRecursiveEasy to understandUses recursion stackIterativeBetter interview practiceSlightly harder logicInterview ExplanationIn interviews, explain:Postorder traversal processes nodes in Left → Right → Root order. Recursion naturally handles this traversal. Iteratively, we simulate recursion using a stack and reverse traversal order.This demonstrates strong tree traversal understanding.Common Mistakes1. Wrong Traversal OrderIncorrect:Root → Left → RightThat is preorder traversal.Correct postorder:Left → Right → Root2. Forgetting Null Base CaseAlways check:if(root == null) return;3. Incorrect Stack Push OrderFor iterative solution:Push left firstPush right secondbecause we reverse the result later.FAQsQ1. Why is postorder traversal useful?It is used in:Tree deletionExpression tree evaluationBottom-up dynamic programmingCalculating subtree informationQ2. Which approach is preferred in interviews?Recursive is simpler.Iterative is often asked as a follow-up.Q3. Can postorder traversal be done without stack or recursion?Yes.Using Morris Traversal.Q4. What is the difference between preorder, inorder, and postorder?TraversalOrderPreorderRoot → Left → RightInorderLeft → Root → RightPostorderLeft → Right → RootBonus: Morris Postorder TraversalMorris traversal performs tree traversal using:O(1)extra space.This is considered an advanced interview topic.ConclusionLeetCode 145 is an excellent beginner-friendly tree traversal problem.It teaches:DFS traversalRecursionStack simulationBinary tree fundamentalsThe key postorder pattern is:Left → Right → RootMastering this traversal helps in solving many advanced tree problems such as:Tree DPTree deletionExpression evaluationSubtree calculationsAdvanced DFS problems