Recursion in Java - Complete Guide With Examples and Practice Problems
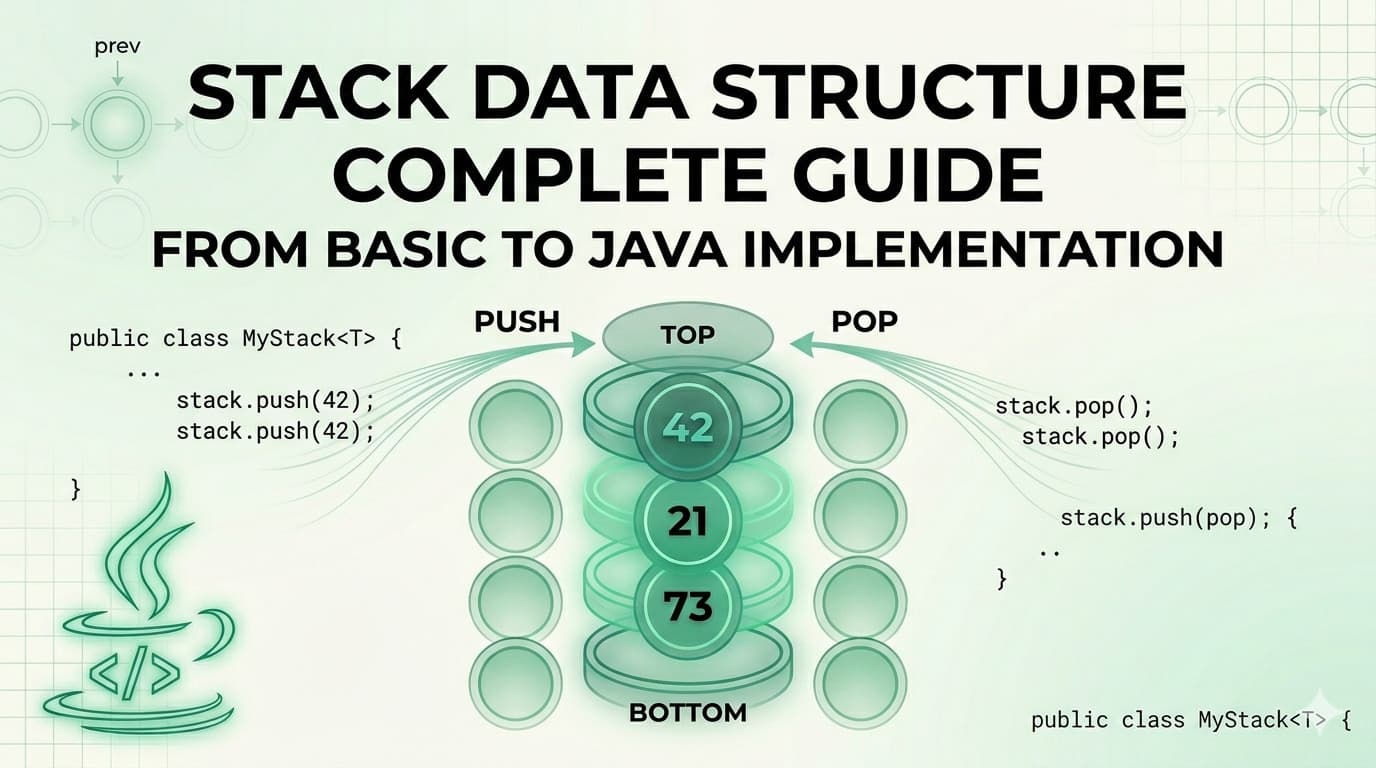
IntroductionIf there is one topic in programming that confuses beginners more than anything else, it is recursion. Most people read the definition, nod their head, and then immediately freeze when they have to write recursive code themselves.The problem is not that recursion is genuinely hard. The problem is that most explanations start with code before building the right mental model. Once you have the right mental model, recursion clicks permanently and you start seeing it everywhere — in tree problems, graph problems, backtracking, dynamic programming, divide and conquer, and more.This guide covers everything from the ground up. What recursion is, how the call stack works, how to identify base cases and recursive cases, every type of recursion, common patterns, time and space complexity analysis, the most common mistakes, and the top LeetCode problems to practice.By the end of this article, recursion will not feel like magic anymore. It will feel like a natural tool you reach for confidently.What Is Recursion?Recursion is when a function calls itself to solve a smaller version of the same problem.That is the complete definition. But let us make it concrete.Imagine you want to count down from 5 to 1. One way is a loop. Another way is — print 5, then solve the exact same problem for counting down from 4 to 1. Then print 4, solve for 3. And so on until you reach the base — there is nothing left to count down.void countDown(int n) { if (n == 0) return; // stop here System.out.println(n); countDown(n - 1); // solve the smaller version}The function countDown calls itself with a smaller input each time. Eventually it reaches 0 and stops. That stopping condition is the most important part of any recursive function — the base case.The Two Parts Every Recursive Function Must HaveEvery correctly written recursive function has exactly two parts. Without both, the function either gives wrong answers or runs forever.Part 1: Base CaseThe base case is the condition under which the function stops calling itself and returns a direct answer. It is the smallest version of the problem that you can solve without any further recursion.Without a base case, recursion never stops and you get a StackOverflowError — Java's way of telling you the call stack ran out of memory.Part 2: Recursive CaseThe recursive case is where the function calls itself with a smaller or simpler input — moving closer to the base case with each call. If your recursive case does not make the problem smaller, you have an infinite loop.Think of it like a staircase. The base case is the ground floor. The recursive case is each step going down. Every step must genuinely bring you one level closer to the ground.How Recursion Works — The Call StackThis is the mental model that most explanations skip, and it is the reason recursion confuses people.Every time a function is called in Java, a new stack frame is created and pushed onto the call stack. This frame stores the function's local variables, parameters, and where to return to when the function finishes.When a recursive function calls itself, a new frame is pushed on top. When that call finishes, its frame is popped and execution returns to the previous frame.Let us trace countDown(3) through the call stack:countDown(3) called → frame pushed prints 3 calls countDown(2) → frame pushed prints 2 calls countDown(1) → frame pushed prints 1 calls countDown(0) → frame pushed n == 0, return → frame popped back in countDown(1), return → frame popped back in countDown(2), return → frame popped back in countDown(3), return → frame poppedOutput: 3, 2, 1The call stack grows as calls go deeper, then shrinks as calls return. This is why recursion uses O(n) space for n levels deep — each level occupies one stack frame in memory.Your First Real Recursive Function — FactorialFactorial is the classic first recursion example. n! = n × (n-1) × (n-2) × ... × 1Notice the pattern — n! = n × (n-1)!. The factorial of n is n times the factorial of n-1. That recursive structure makes it perfect for recursion.public int factorial(int n) { // base case if (n == 0 || n == 1) return 1; // recursive case return n * factorial(n - 1);}Dry Run — factorial(4)factorial(4)= 4 * factorial(3)= 4 * 3 * factorial(2)= 4 * 3 * 2 * factorial(1)= 4 * 3 * 2 * 1= 24The call stack builds up going in, then multiplications happen coming back out. This "coming back out" phase is called the return phase or unwinding of the stack.Time Complexity: O(n) — n recursive calls Space Complexity: O(n) — n frames on the call stackThe Two Phases of RecursionEvery recursive function has two phases and understanding both is critical.Phase 1: The Call Phase (Going In)This happens as the function keeps calling itself with smaller inputs. Things you do before the recursive call happen in this phase — in order from the outermost call to the innermost.Phase 2: The Return Phase (Coming Back Out)This happens as each call finishes and returns to its caller. Things you do after the recursive call happen in this phase — in reverse order, from the innermost call back to the outermost.This distinction explains why the output order can be surprising:void printBothPhases(int n) { if (n == 0) return; System.out.println("Going in: " + n); // call phase printBothPhases(n - 1); System.out.println("Coming out: " + n); // return phase}For printBothPhases(3):Going in: 3Going in: 2Going in: 1Coming out: 1Coming out: 2Coming out: 3This two-phase understanding is what makes problems like reversing a string or printing a linked list backwards via recursion feel natural.Types of RecursionRecursion is not one-size-fits-all. There are several distinct types and knowing which type applies to a problem shapes how you write the solution.1. Direct RecursionThe function calls itself directly. This is the most common type — what we have seen so far.void direct(int n) { if (n == 0) return; direct(n - 1); // calls itself}2. Indirect RecursionFunction A calls Function B which calls Function A. They form a cycle.void funcA(int n) { if (n <= 0) return; System.out.println("A: " + n); funcB(n - 1);}void funcB(int n) { if (n <= 0) return; System.out.println("B: " + n); funcA(n - 1);}Used in: state machines, mutual recursion in parsers, certain mathematical sequences.3. Tail RecursionThe recursive call is the last operation in the function. Nothing happens after the recursive call returns — no multiplication, no addition, nothing.// NOT tail recursive — multiplication happens after returnint factorial(int n) { if (n == 1) return 1; return n * factorial(n - 1); // multiply after return — not tail}// Tail recursive — recursive call is the last thingint factorialTail(int n, int accumulator) { if (n == 1) return accumulator; return factorialTail(n - 1, n * accumulator); // last operation}Why does tail recursion matter? In languages that support tail call optimization (like Scala, Kotlin, and many functional languages), tail recursive functions can be converted to iteration internally — no stack frame accumulation, O(1) space. Java does NOT perform tail call optimization, but understanding tail recursion is still important for interviews and functional programming concepts.4. Head RecursionThe recursive call happens first, before any other processing. All processing happens in the return phase.void headRecursion(int n) { if (n == 0) return; headRecursion(n - 1); // call first System.out.println(n); // process after}// Output: 1 2 3 4 5 (processes in reverse order of calls)5. Tree RecursionThe function makes more than one recursive call per invocation. This creates a tree of calls rather than a linear chain. Fibonacci is the classic example.int fibonacci(int n) { if (n <= 1) return n; return fibonacci(n - 1) + fibonacci(n - 2); // TWO recursive calls}The call tree for fibonacci(4): fib(4) / \ fib(3) fib(2) / \ / \ fib(2) fib(1) fib(1) fib(0) / \ fib(1) fib(0)Time Complexity: O(2ⁿ) — exponential! Each call spawns two more. Space Complexity: O(n) — maximum depth of the call treeThis is why memoization (caching results) is so important for tree recursion — it converts O(2ⁿ) to O(n) by never recomputing the same subproblem twice.6. Mutual RecursionA specific form of indirect recursion where two functions call each other alternately to solve a problem. Different from indirect recursion in that the mutual calls are the core mechanism of the solution.// Check if a number is even or odd using mutual recursionboolean isEven(int n) { if (n == 0) return true; return isOdd(n - 1);}boolean isOdd(int n) { if (n == 0) return false; return isEven(n - 1);}Common Recursion Patterns in DSAThese are the patterns you will see over and over in interview problems. Recognizing them is more important than memorizing solutions.Pattern 1: Linear Recursion (Do Something, Recurse on Rest)Process the current element, then recurse on the remaining problem.// Sum of arrayint arraySum(int[] arr, int index) { if (index == arr.length) return 0; // base case return arr[index] + arraySum(arr, index + 1); // current + rest}Pattern 2: Divide and Conquer (Split Into Two Halves)Split the problem into two halves, solve each recursively, combine results.// Merge Sortvoid mergeSort(int[] arr, int left, int right) { if (left >= right) return; // base case — single element int mid = (left + right) / 2; mergeSort(arr, left, mid); // sort left half mergeSort(arr, mid + 1, right); // sort right half merge(arr, left, mid, right); // combine}Pattern 3: Backtracking (Try, Recurse, Undo)Try a choice, recurse to explore it, undo the choice when backtracking.// Generate all subsetsvoid subsets(int[] nums, int index, List<Integer> current, List<List<Integer>> result) { if (index == nums.length) { result.add(new ArrayList<>(current)); return; } // Choice 1: include nums[index] current.add(nums[index]); subsets(nums, index + 1, current, result); current.remove(current.size() - 1); // undo // Choice 2: exclude nums[index] subsets(nums, index + 1, current, result);}Pattern 4: Tree Recursion (Left, Right, Combine)Recurse on left subtree, recurse on right subtree, combine or process results.// Height of binary treeint height(TreeNode root) { if (root == null) return 0; // base case int leftHeight = height(root.left); // solve left int rightHeight = height(root.right); // solve right return 1 + Math.max(leftHeight, rightHeight); // combine}Pattern 5: Memoization (Cache Recursive Results)Store results of recursive calls so the same subproblem is never solved twice.Map<Integer, Integer> memo = new HashMap<>();int fibonacci(int n) { if (n <= 1) return n; if (memo.containsKey(n)) return memo.get(n); // return cached int result = fibonacci(n - 1) + fibonacci(n - 2); memo.put(n, result); // cache before returning return result;}This converts Fibonacci from O(2ⁿ) to O(n) time with O(n) space — a massive improvement.Recursion vs Iteration — When to Use WhichThis is one of the most common interview questions about recursion. Here is a clear breakdown:Use Recursion when:The problem has a naturally recursive structure (trees, graphs, divide and conquer)The solution is significantly cleaner and easier to understand recursivelyThe problem involves exploring multiple paths or choices (backtracking)The depth of recursion is manageable (not too deep to cause stack overflow)Use Iteration when:The problem is linear and a loop is equally clearMemory is a concern (iteration uses O(1) stack space vs O(n) for recursion)Performance is critical and function call overhead mattersJava's stack size limit could be hit (default around 500-1000 frames for deep recursion)The key rule: Every recursive solution can be converted to an iterative one (usually using an explicit stack). But recursive solutions for tree and graph problems are almost always cleaner to write and understand.Time and Space Complexity of Recursive FunctionsAnalyzing complexity for recursive functions requires a specific approach.The Recurrence Relation MethodExpress the time complexity as a recurrence relation and solve it.Factorial:T(n) = T(n-1) + O(1) = T(n-2) + O(1) + O(1) = T(1) + n×O(1) = O(n)Fibonacci (naive):T(n) = T(n-1) + T(n-2) + O(1) ≈ 2×T(n-1) = O(2ⁿ)Binary Search:T(n) = T(n/2) + O(1) = O(log n) [by Master Theorem]Merge Sort:T(n) = 2×T(n/2) + O(n) = O(n log n) [by Master Theorem]Space Complexity Rule for RecursionSpace complexity of a recursive function = maximum depth of the call stack × space per frameLinear recursion (factorial, sum): O(n) spaceBinary recursion (Fibonacci naive): O(n) space (maximum depth, not number of nodes)Divide and conquer (merge sort): O(log n) space (depth of recursion tree)Memoized Fibonacci: O(n) space (memo table + call stack)Classic Recursive Problems With SolutionsProblem 1: Reverse a StringString reverse(String s) { if (s.length() <= 1) return s; // base case // last char + reverse of everything before last char return s.charAt(s.length() - 1) + reverse(s.substring(0, s.length() - 1));}Dry run for "hello":reverse("hello") = 'o' + reverse("hell")reverse("hell") = 'l' + reverse("hel")reverse("hel") = 'l' + reverse("he")reverse("he") = 'e' + reverse("h")reverse("h") = "h"Unwinding: "h" → "he" → "leh" → "lleh" → "olleh" ✅Problem 2: Power Function (x^n)double power(double x, int n) { if (n == 0) return 1; // base case if (n < 0) return 1.0 / power(x, -n); // handle negative if (n % 2 == 0) { double half = power(x, n / 2); return half * half; // x^n = (x^(n/2))^2 } else { return x * power(x, n - 1); }}This is the fast power algorithm — O(log n) time instead of O(n).Problem 3: Fibonacci With Memoizationint[] memo = new int[100];Arrays.fill(memo, -1);int fib(int n) { if (n <= 1) return n; if (memo[n] != -1) return memo[n]; memo[n] = fib(n - 1) + fib(n - 2); return memo[n];}Time: O(n) — each value computed once Space: O(n) — memo array + call stackProblem 4: Tower of HanoiThe classic recursion teaching problem. Move n disks from source to destination using a helper rod.void hanoi(int n, char source, char destination, char helper) { if (n == 1) { System.out.println("Move disk 1 from " + source + " to " + destination); return; } // Move n-1 disks from source to helper hanoi(n - 1, source, helper, destination); // Move the largest disk from source to destination System.out.println("Move disk " + n + " from " + source + " to " + destination); // Move n-1 disks from helper to destination hanoi(n - 1, helper, destination, source);}Time Complexity: O(2ⁿ) — minimum moves required is 2ⁿ - 1 Space Complexity: O(n) — call stack depthProblem 5: Generate All Subsets (Power Set)void generateSubsets(int[] nums, int index, List<Integer> current, List<List<Integer>> result) { result.add(new ArrayList<>(current)); // add current subset for (int i = index; i < nums.length; i++) { current.add(nums[i]); // include generateSubsets(nums, i + 1, current, result); // recurse current.remove(current.size() - 1); // exclude (backtrack) }}For [1, 2, 3] — generates all 8 subsets: [], [1], [1,2], [1,2,3], [1,3], [2], [2,3], [3]Time: O(2ⁿ) — 2ⁿ subsets Space: O(n) — recursion depthProblem 6: Binary Search Recursivelyint binarySearch(int[] arr, int target, int left, int right) { if (left > right) return -1; // base case — not found int mid = left + (right - left) / 2; if (arr[mid] == target) return mid; else if (arr[mid] < target) return binarySearch(arr, target, mid + 1, right); else return binarySearch(arr, target, left, mid - 1);}Time: O(log n) — halving the search space each time Space: O(log n) — log n frames on the call stackRecursion on Trees — The Natural HabitatTrees are where recursion truly shines. Every tree problem becomes elegant with recursion because a tree is itself a recursive structure — each node's left and right children are trees themselves.// Maximum depth of binary treeint maxDepth(TreeNode root) { if (root == null) return 0; return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));}// Check if tree is symmetricboolean isSymmetric(TreeNode left, TreeNode right) { if (left == null && right == null) return true; if (left == null || right == null) return false; return left.val == right.val && isSymmetric(left.left, right.right) && isSymmetric(left.right, right.left);}// Path sum — does any root-to-leaf path sum to target?boolean hasPathSum(TreeNode root, int target) { if (root == null) return false; if (root.left == null && root.right == null) return root.val == target; return hasPathSum(root.left, target - root.val) || hasPathSum(root.right, target - root.val);}Notice the pattern in all three — base case handles null, recursive case handles left and right subtrees, result combines both.How to Think About Any Recursive Problem — Step by StepThis is the framework you should apply to every new recursive problem you encounter:Step 1 — Identify the base case What is the smallest input where you know the answer directly without any recursion? For arrays it is usually empty array or single element. For trees it is null node. For numbers it is 0 or 1.Step 2 — Trust the recursive call Assume your function already works correctly for smaller inputs. Do not trace through the entire recursion mentally — just trust it. This is the Leap of Faith and it is what makes recursion feel natural.Step 3 — Express the current problem in terms of smaller problems How does the answer for size n relate to the answer for size n-1 (or n/2, or subtrees)? This relationship is your recursive case.Step 4 — Make sure each call moves toward the base case The input must become strictly smaller with each call. If it does not, you have infinite recursion.Step 5 — Write the base case first, then the recursive case Always. Writing the recursive case first leads to bugs because you have not defined when to stop.Common Mistakes and How to Avoid ThemMistake 1: Missing or wrong base case The most common mistake. Missing the base case causes StackOverflowError. Wrong base case causes wrong answers.Always ask — what is the simplest possible input, and what should the function return for it? Write that case first.Mistake 2: Not moving toward the base case If you call factorial(n) inside factorial(n) without reducing n, you loop forever. Every recursive call must make the problem strictly smaller.Mistake 3: Trusting your brain to trace deep recursion Do not try to trace 10 levels of recursion in your head. Trust the recursive call, verify the base case, and check that each call reduces the problem. That is all you need.Mistake 4: Forgetting to return the recursive result// WRONG — result is computed but not returnedint sum(int n) { if (n == 0) return 0; sum(n - 1) + n; // computed but discarded!}// CORRECTint sum(int n) { if (n == 0) return 0; return sum(n - 1) + n;}Mistake 5: Modifying shared state without backtracking In backtracking problems, if you add something to a list before a recursive call, you must remove it after the call returns. Forgetting to backtrack leads to incorrect results and is one of the trickiest bugs to find.Mistake 6: Recomputing the same subproblems Naive Fibonacci computes fib(3) multiple times when computing fib(5). Use memoization whenever you notice overlapping subproblems in your recursion tree.Top LeetCode Problems on RecursionThese are organized by pattern — work through them in this order for maximum learning:Pure Recursion Basics:509. Fibonacci Number — Easy — start here, implement with and without memoization344. Reverse String — Easy — recursion on arrays206. Reverse Linked List — Easy — recursion on linked list50. Pow(x, n) — Medium — fast power with recursionTree Recursion (Most Important):104. Maximum Depth of Binary Tree — Easy — simplest tree recursion112. Path Sum — Easy — decision recursion on tree101. Symmetric Tree — Easy — mutual recursion on tree110. Balanced Binary Tree — Easy — bottom-up recursion236. Lowest Common Ancestor of a Binary Tree — Medium — classic tree recursion124. Binary Tree Maximum Path Sum — Hard — advanced tree recursionDivide and Conquer:148. Sort List — Medium — merge sort on linked list240. Search a 2D Matrix II — Medium — divide and conquerBacktracking:78. Subsets — Medium — generate all subsets46. Permutations — Medium — generate all permutations77. Combinations — Medium — generate combinations79. Word Search — Medium — backtracking on grid51. N-Queens — Hard — classic backtrackingMemoization / Dynamic Programming:70. Climbing Stairs — Easy — Fibonacci variant with memoization322. Coin Change — Medium — recursion with memoization to DP139. Word Break — Medium — memoized recursionRecursion Cheat Sheet// Linear recursion templatereturnType solve(input) { if (baseCase) return directAnswer; // process current return solve(smallerInput);}// Tree recursion templatereturnType solve(TreeNode root) { if (root == null) return baseValue; returnType left = solve(root.left); returnType right = solve(root.right); return combine(left, right, root.val);}// Backtracking templatevoid backtrack(choices, current, result) { if (goalReached) { result.add(copy of current); return; } for (choice : choices) { make(choice); // add to current backtrack(...); // recurse undo(choice); // remove from current }}// Memoization templateMap<Input, Output> memo = new HashMap<>();returnType solve(input) { if (baseCase) return directAnswer; if (memo.containsKey(input)) return memo.get(input); returnType result = solve(smallerInput); memo.put(input, result); return result;}FAQs — People Also AskQ1. What is recursion in Java with a simple example? Recursion is when a function calls itself to solve a smaller version of the same problem. A simple example is factorial — factorial(5) = 5 × factorial(4) = 5 × 4 × factorial(3) and so on until factorial(1) returns 1 directly.Q2. What is the difference between recursion and iteration? Iteration uses loops (for, while) and runs in O(1) space. Recursion uses function calls and uses O(n) stack space for n levels deep. Recursion is often cleaner for tree and graph problems. Iteration is better when memory is a concern or the problem is inherently linear.Q3. What causes StackOverflowError in Java recursion? StackOverflowError happens when recursion goes too deep — too many frames accumulate on the call stack before any of them return. This is caused by missing base case, wrong base case, or input too large for Java's default stack size limit.Q4. What is the difference between recursion and dynamic programming? Recursion solves a problem by breaking it into subproblems. Dynamic programming is recursion plus memoization — storing results of subproblems so they are never computed twice. DP converts exponential recursive solutions into polynomial ones by eliminating redundant computation.Q5. What is tail recursion and does Java support tail call optimization? Tail recursion is when the recursive call is the absolute last operation in the function. Java does NOT support tail call optimization — Java always creates a new stack frame for each call even if it is tail recursive. Languages like Scala and Kotlin (on the JVM) do support it with the tailrec keyword.Q6. How do you convert recursion to iteration? Every recursive solution can be converted to iterative using an explicit stack data structure. The call stack's behavior is replicated manually — push the initial call, loop while stack is not empty, pop, process, and push sub-calls. Tree traversals are a common example of this conversion.ConclusionRecursion is not magic. It is a systematic way of solving problems by expressing them in terms of smaller versions of themselves. Once you internalize the two parts (base case and recursive case), understand the call stack mentally, and learn to trust the recursive call rather than trace it completely, everything clicks.The learning path from here is clear — start with simple problems like Fibonacci and array sum. Move to tree problems where recursion is most natural. Then tackle backtracking. Finally add memoization to bridge into dynamic programming.Every hour you spend understanding recursion deeply pays dividends across the entire rest of your DSA journey. Trees, graphs, divide and conquer, backtracking, dynamic programming — all of them build on this foundation.