LeetCode 1614: Maximum Nesting Depth of Parentheses — Java Solution Explained
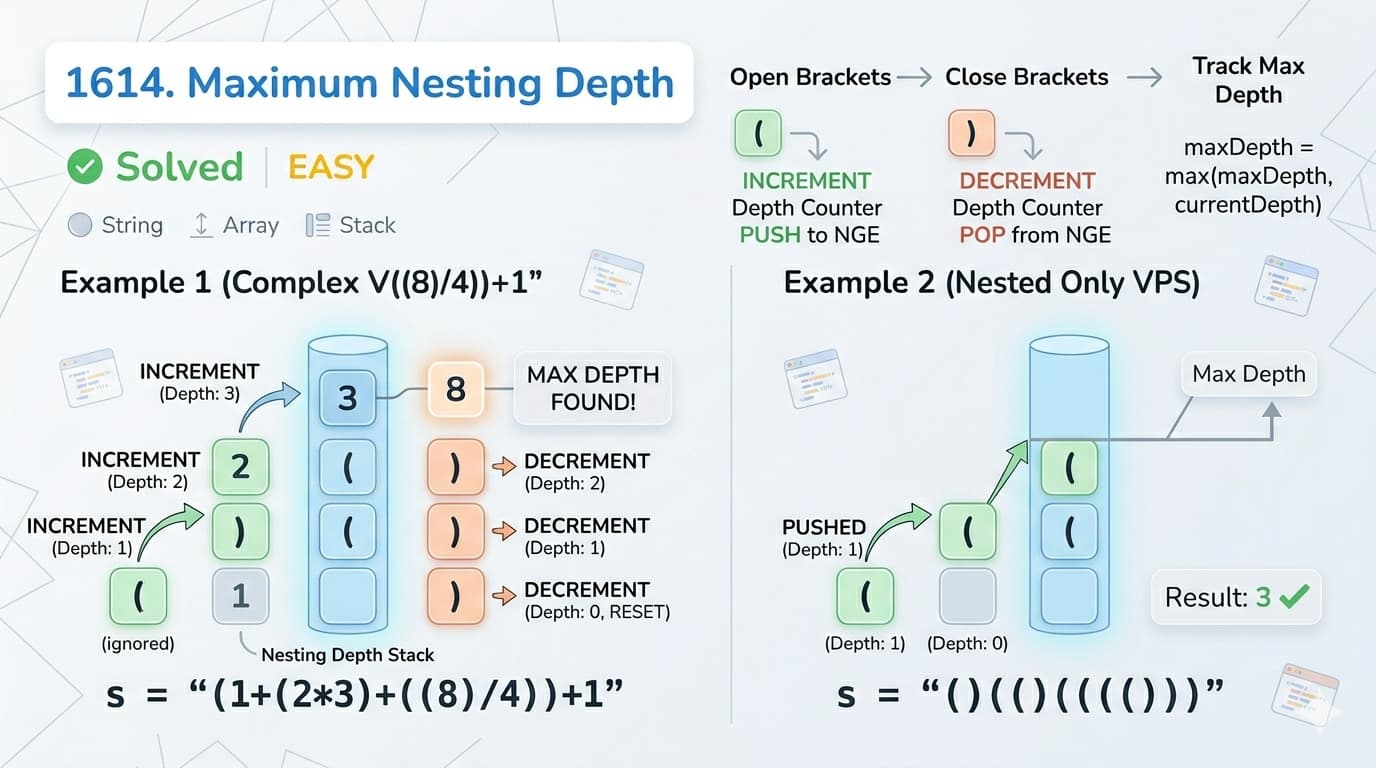
IntroductionLeetCode 1614 Maximum Nesting Depth of Parentheses is a natural follow-up to LeetCode 20 Valid Parentheses. While LeetCode 20 asks "are the brackets valid?", this problem asks "how deeply are they nested?" It is a clean, focused problem that teaches you how to think about bracket depth — a concept that appears in compilers, parsers, JSON validators, and XML processors in real world software.Here is the Link of Question -: LeetCode 1614In this article we cover plain English explanation, real life analogy, two Java approaches with dry runs, complexity analysis, and all the important details you need for interviews.What Is the Problem Really Asking?You are given a valid parentheses string. You need to find the maximum number of nested (not just sequential) open parentheses at any point in the string.The key distinction here is nested vs sequential:"()()()" → depth is 1, brackets are sequential not nested"((()))" → depth is 3, brackets are fully nested inside each other"()(())" → depth is 2, the second pair is nested one level deepReal Life Analogy — Folders Inside FoldersThink of your computer's file system. You have a folder, inside that a subfolder, inside that another subfolder. The depth is how many folders deep you are at the deepest point."(1+(2*3)+((8)/4))+1" is like:Outer folder ( → depth 1Inner folder ( inside it → depth 2Innermost folder (( → depth 3The answer is how deep the deepest file is buried. You do not care about other folders — just the maximum depth reached at any single moment.Approach 1: Stack Based Solution (Classic)The IdeaUse a stack exactly like LeetCode 20. Every time you push an opening bracket, increment a counter. Every time you pop a closing bracket, record the max before decrementing. The stack size at any moment represents current depth.public int maxDepth(String s) { Stack<Character> st = new Stack<>(); int current = 0; int max = 0; for (int i = 0; i < s.length(); i++) { char c = s.charAt(i); if (c == '(') { st.push(c); current++; max = Math.max(max, current); // record depth when going deeper } else if (c == ')') { if (!st.empty() && st.peek() == '(') { max = Math.max(max, current); current--; st.pop(); } } } return max;}Dry Run — s = "()(())((()()))"( → push, current = 1, max = 1) → pop, current = 0( → push, current = 1, max = 1( → push, current = 2, max = 2) → pop, current = 1) → pop, current = 0( → push, current = 1, max = 2( → push, current = 2, max = 2( → push, current = 3, max = 3 ✅) → pop, current = 2( → push, current = 3, max = 3) → pop, current = 2) → pop, current = 1) → pop, current = 0✅ Output: 3Time Complexity: O(n) — single pass Space Complexity: O(n) — stack holds up to n/2 opening bracketsApproach 2: Counter Only — No Stack (Optimal) ✅The IdeaThis is the smartest approach and the real insight of this problem. You do not actually need a stack at all! Think about it — the depth at any moment is simply how many unmatched opening brackets we have seen so far. That is just a counter!( → increment counter, update max) → decrement counterEverything else → ignorepublic int maxDepth(String s) { int current = 0; int max = 0; for (int i = 0; i < s.length(); i++) { if (s.charAt(i) == '(') { current++; max = Math.max(max, current); } else if (s.charAt(i) == ')') { current--; } } return max;}This is beautifully simple. No stack, no extra memory, just two integer variables.Dry Run — s = "(1+(2*3)+((8)/4))+1"Only tracking ( and ), ignoring digits and operators:( → current = 1, max = 1( → current = 2, max = 2) → current = 1( → current = 2, max = 2( → current = 3, max = 3 ✅) → current = 2) → current = 1) → current = 0✅ Output: 3Time Complexity: O(n) — single pass Space Complexity: O(1) — only two integer variables, no extra storage!Why Update Max on ( Not on )?This is the most important implementation detail. You update max when you open a bracket, not when you close it. Why?Because when you encounter (, your depth just increased to a new level — that is when you might have hit a new maximum. When you encounter ), you are going back up — depth is decreasing, so it can never be a new maximum.Always capture the peak on the way down into nesting, not on the way back out.Stack vs Counter — Which to Use?The counter approach is strictly better here — same time complexity but O(1) space instead of O(n). In an interview, start by mentioning the stack approach to show you recognize the stack pattern, then immediately offer the counter optimization to show deeper understanding.This mirrors the same progression as LeetCode 844 Backspace String Compare — where the O(1) two pointer follow-up impressed interviewers more than the standard stack solution.How This Fits the Stack Pattern SeriesLooking at the full series you have been solving:20 Valid Parentheses — are brackets correctly matched? 1614 Maximum Nesting Depth — how deeply are they nested?These two problems are complementary. One validates structure, the other measures depth. Together they cover the two most fundamental questions you can ask about a bracket string. Real world parsers need to answer both — "is this valid?" and "how complex is the nesting?"Common Mistakes to AvoidUpdating max after decrementing on ) If you write current-- before Math.max, you will always be one level too low and miss the true maximum. Always capture max before or at the moment of increment, never after decrement.Counting all characters not just brackets Digits, operators like +, -, *, / must be completely ignored. Only ( and ) affect depth.Using a Stack when a counter suffices Since the problem guarantees a valid parentheses string, you never need to validate matching — just track depth. A Stack adds unnecessary complexity and memory overhead here.FAQs — People Also AskQ1. What is nesting depth in LeetCode 1614? Nesting depth is the maximum number of open parentheses that are simultaneously unclosed at any point in the string. For example "((()))" has depth 3 because at the innermost point, three ( are open at the same time.Q2. What is the best approach for LeetCode 1614 in Java? The counter approach is optimal — O(n) time and O(1) space. Increment a counter on (, update max, decrement on ). No stack needed since the string is guaranteed to be a valid parentheses string.Q3. What is the time complexity of LeetCode 1614? Both approaches are O(n) time. The Stack approach uses O(n) space while the counter approach uses O(1) space, making the counter approach strictly better.Q4. What is the difference between LeetCode 20 and LeetCode 1614? LeetCode 20 validates whether a bracket string is correctly formed. LeetCode 1614 assumes the string is already valid and asks how deeply the brackets are nested. LeetCode 20 needs a stack for matching; LeetCode 1614 only needs a counter.Q5. Is LeetCode 1614 asked in coding interviews? It appears occasionally as a warmup or follow-up after LeetCode 20. The more important skill it tests is recognizing when a stack can be replaced by a simpler counter — that kind of space optimization thinking is valued in interviews.Similar LeetCode Problems to Practice Next20. Valid Parentheses — Easy — validate bracket structure1021. Remove Outermost Parentheses — Easy — depth-based filtering1249. Minimum Remove to Make Valid Parentheses — Medium — remove minimum brackets32. Longest Valid Parentheses — Hard — longest valid substring394. Decode String — Medium — nested brackets with encodingConclusionLeetCode 1614 Maximum Nesting Depth of Parentheses teaches a deceptively simple but important lesson — not every bracket problem needs a stack. When the string is guaranteed valid and you only need to measure depth, a counter is all you need.The progression from LeetCode 20 to 1614 perfectly illustrates how understanding the core problem deeply leads to elegant simplifications. Master both, understand why one needs a stack and the other does not, and you will have a strong foundation for every bracket problem in your interview journey.