LeetCode 2657: Find the Prefix Common Array of Two Arrays – Java Hashing Solution Explained
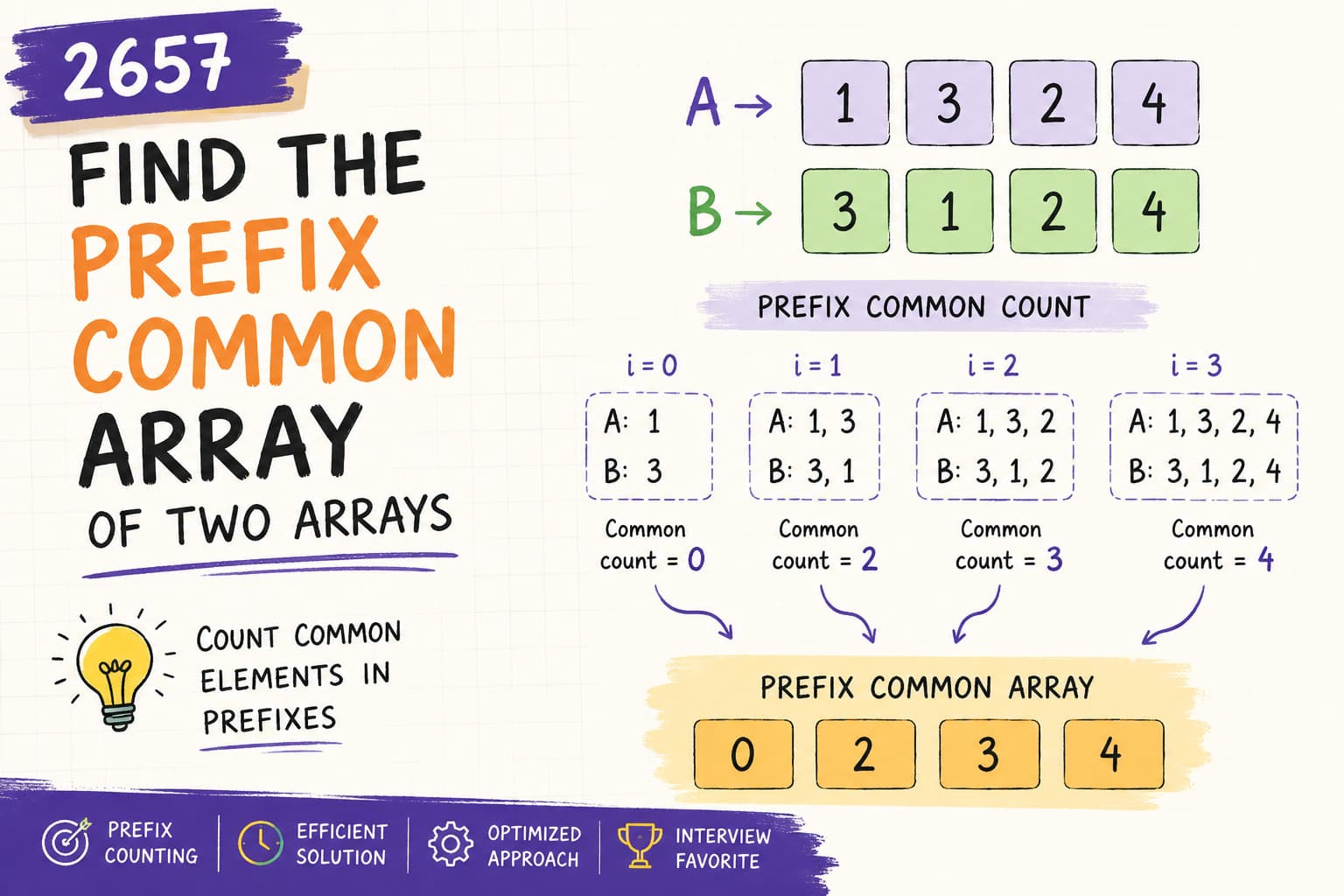
IntroductionLeetCode 2657 – Find the Prefix Common Array of Two Arrays is an interesting prefix and hashing problem that tests your understanding of:Prefix processingHashingFrequency countingSet operationsArray traversalAt first glance, the problem may look confusing because of the term:Prefix Common ArrayBut once you understand the meaning of prefixes and common elements, the problem becomes straightforward.This problem is useful for improving:Prefix-based thinkingHashing intuitionOptimization skillsInterview problem-solving abilityProblem Link🔗 Find the prefix Common Array of Two ArraysProblem StatementYou are given two permutations:A and BBoth arrays contain numbers:1 to nexactly once.You need to create an array:Cwhere:C[i]represents:Count of numbers present in both arrays from index 0 to i.Understanding Prefix Common ArraySuppose:A = [1,3,2,4]B = [3,1,2,4]Prefix at Index 0A Prefix = [1]B Prefix = [3]Common numbers:NoneSo:C[0] = 0Prefix at Index 1A Prefix = [1,3]B Prefix = [3,1]Common numbers:1, 3So:C[1] = 2Final Output[0,2,3,4]Key ObservationBoth arrays are permutations.This means:Every number appears exactly once.Once a number appears in both prefixes, it remains common forever.This simplifies the logic significantly.Brute Force ApproachIntuitionFor every index:Build prefixesCompare elementsCount common numbersBrute Force AlgorithmFor each index:Traverse all previous elementsCheck whether numbers exist in both prefixesCount matchesBrute Force ComplexityTime ComplexityO(N²)because for every index we may scan previous elements.Space ComplexityO(N)Understanding ApproachThis approach uses:HashMapPrefix trackingCounting common valuesThe idea is:Store prefix elements from BTraverse A prefixCount matching numbersThis works because prefixes gradually expand.Java Solutionclass Solution { public int[] findThePrefixCommonArray(int[] A, int[] B) { int j = 0; int[] ans = new int[A.length]; HashMap<Integer, Integer> map = new HashMap<>(); for(int i = 0; i < A.length; i++) { map.put(B[i], i); int counter = 0; int c = 0; for(int a : map.keySet()) { if(map.containsKey(A[c])) { counter++; } c++; } ans[j] = counter; j++; } return ans; }}Better Optimized ApproachWe can solve this more cleanly using:HashSetor frequency counting.Optimized IntuitionAt every index:Add A[i]Add B[i]Track which numbers appearedIf a number appears in both arrays, increase common countBest Optimized Approach Using Frequency ArrayBecause values are from:1 to nwe can use a frequency array.Optimized Java Solutionclass Solution { public int[] findThePrefixCommonArray(int[] A, int[] B) { int n = A.length; int[] ans = new int[n]; int[] freq = new int[n + 1]; int common = 0; for(int i = 0; i < n; i++) { freq[A[i]]++; if(freq[A[i]] == 2) common++; freq[B[i]]++; if(freq[B[i]] == 2) common++; ans[i] = common; } return ans; }}Why Does This Work?Every number appears once in A and once in B.So:First appearance → frequency becomes 1Second appearance → frequency becomes 2When frequency becomes:2it means the number has appeared in both prefixes.So we increase:commonDry RunInputA = [1,3,2,4]B = [3,1,2,4]Step 1Index:0Add:1 and 3Frequencies:1 → 13 → 1No common elements.ans[0] = 0Step 2Add:3 and 1Frequencies:1 → 23 → 2Two common elements found.ans[1] = 2Step 3Add:2 and 2Frequency:2 → 2Common becomes:3ans[2] = 3Step 4Add:4 and 4Frequency:4 → 2Common becomes:4ans[3] = 4Final Output[0,2,3,4]Time Complexity AnalysisTime ComplexityO(N²)Nested traversal inside loop.Space ComplexityO(N)Optimized Frequency ApproachTime ComplexityO(N)Single traversal.Space ComplexityO(N)Frequency array.HashMap vs Frequency ArrayApproachTime ComplexitySpace ComplexityHashMapO(N²)O(N)Frequency ArrayO(N)O(N)Interview ExplanationIn interviews, explain:Since both arrays are permutations, every number appears exactly twice overall — once in A and once in B. Using frequency counting, whenever a number’s frequency becomes 2, it means it has appeared in both prefixes.This demonstrates:Prefix understandingOptimization thinkingHashing skillsCommon Mistakes1. Recalculating Common Elements Every TimeThis causes:O(N²)complexity.2. Forgetting Arrays Are PermutationsThis special condition allows frequency optimization.3. Incorrect Prefix LogicRemember:Prefix means elements from 0 to i.FAQsQ1. Why is this called Prefix Common Array?Because:C[i]stores common elements between prefixes ending at index:iQ2. Why does frequency 2 mean common?Because every number appears once in each array.Q3. Which approach is best?Frequency array approach is the most optimized.Q4. Is this problem important for interviews?Yes.It tests:Prefix logicHashingOptimizationArray traversalRelated ProblemsAfter mastering this problem, practice:Intersection of Two ArraysIntersection of Two Arrays IIContains DuplicateSubarray Sum Equals KPrefix SumFind the Difference of Two ArraysConclusionLeetCode 2657 is an excellent prefix and hashing problem.It teaches:Prefix processingFrequency countingOptimization techniquesHashing fundamentalsThe key insight is:A number becomes common exactly when its frequency becomes 2.Once you understand this observation, the optimized solution becomes very simple and efficient.