Fast and Slow Pointer Technique in Linked List: Cycle Detection, Proof, and Complete Explanation
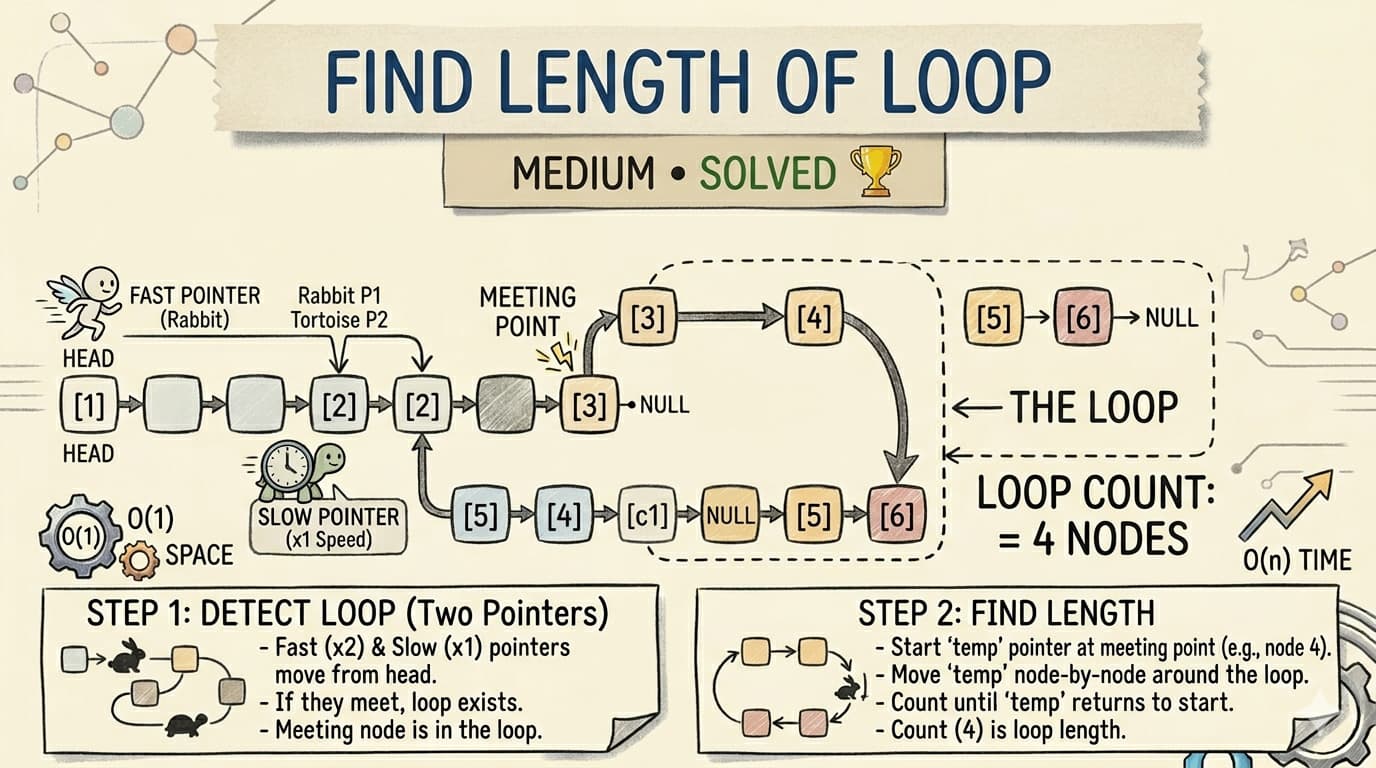
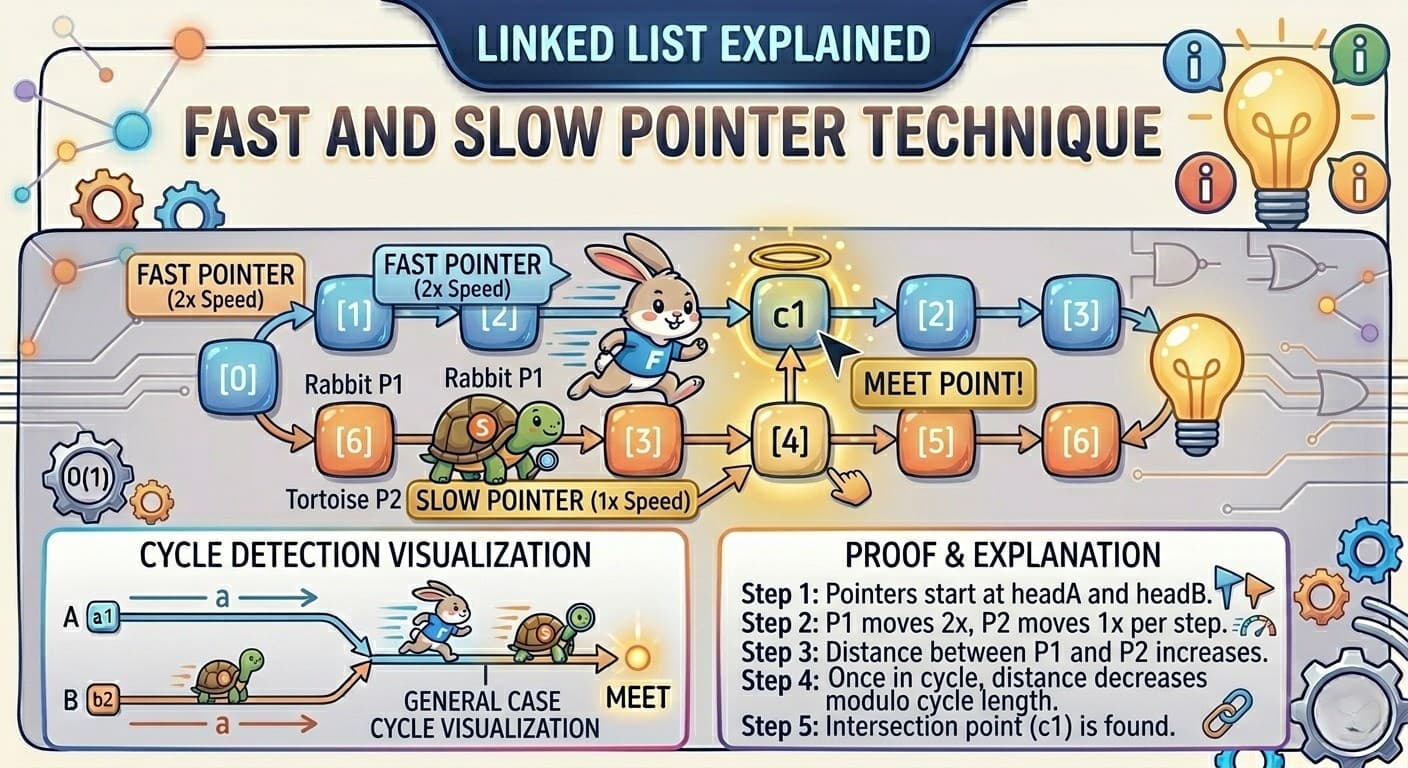
🚀 Before We StartTry these problems (optional but helpful):https://leetcode.com/problems/linked-list-cycle/https://leetcode.com/problems/linked-list-cycle-ii/🤔 Let’s Talk Honestly…When you first learn this technique, you’re told:👉 “Slow moves 1 step, fast moves 2 steps”👉 “If they meet → cycle exists”But your brain asks:❓ Why 2 steps?❓ Why do they meet at all?❓ Why does resetting pointer find cycle start?❓ Is this magic or logic?👉 Let’s answer each doubt one by one.🧩 Doubt 1: Why do we even use two pointers?❓ Question:Why not just use one pointer?✅ Answer:With one pointer:You can only move forwardYou cannot detect loops efficiently👉 Two pointers create a relative motionThat relative motion is the key.🧩 Doubt 2: Why fast = 2 steps and slow = 1 step?❓ Question:Why exactly 2 and 1?✅ Answer:We need:Fast speed > Slow speedSo that:👉 Fast catches up to slow🧠 Think like this:If both move same speed:Slow → 1 stepFast → 1 step👉 They will NEVER meet ❌If:Slow → 1 stepFast → 2 steps👉 Fast gains 1 node every step🔥 Key Insight:Relative speed = fast - slow = 1👉 This means fast is closing the gap by 1 node every step🧩 Doubt 3: Why do they ALWAYS meet in a cycle?❓ Question:Okay, fast is faster… but why guaranteed meeting?🧠 Imagine a Circular TrackInside a cycle, the list behaves like:Circle of length = λNow:Slow moves 1 stepFast moves 2 steps🔄 Gap BehaviorEach step:Gap = Gap - 1Because fast is catching up.Eventually:Gap = 0👉 They meet 🎯💡 Simple AnalogyTwo runners on a circular track:One is fasterOne is slower👉 Faster runner will lap and meet slower runner🧩 Doubt 4: What if there is NO cycle?❓ Question:Why does this fail without cycle?✅ Answer:If no cycle:List ends → fast reaches null👉 No loop → no meeting🧩 Doubt 5: Where do they meet?❓ Question:Do they meet at cycle start?❌ Answer:No, not necessarily.They meet somewhere inside the cycle🧩 Doubt 6: Then how do we find the cycle start?Now comes the most important part.🎯 SetupLet’s define:a = distance from head to cycle startb = distance from cycle start to meeting pointc = remaining cycleCycle length:λ = b + c🧠 What happens when they meet?Slow distance:a + bFast distance:2(a + b)Using relation:2(a + b) = a + b + kλSolve:a + b = kλ=> a = kλ - b=> a = (k-1)λ + (λ - b)💥 Final Meaninga = distance from meeting point to cycle start🔥 BIG CONCLUSION👉 Distance from head → cycle start👉 = Distance from meeting point → cycle start🧩 Doubt 7: Why resetting pointer works?❓ Question:Why move one pointer to head?✅ Answer:Because:One pointer is a away from startOther is also a away (via cycle)👉 Move both 1 step:They meet at:Cycle Start 🎯🔄 VisualizationHead → → → Cycle Start → → Meeting Point → → back to StartBoth pointers:One from headOne from meeting point👉 Same distance → meet at start🧩 Doubt 8: Can we use fast = 3 steps?❓ Question:Will this work?✅ Answer:Yes, BUT:Math becomes complexHarder to reasonNo extra benefit👉 So we use simplest:2 : 1 ratio🧠 Final Mental ModelThink in 3 steps:1. Different SpeedsFast moves faster → gap reduces2. Circular StructureCycle → positions repeat3. Guaranteed MeetingFinite positions + relative motion → collision🧩 TEMPLATE 1: Detect CycleListNode slow = head;ListNode fast = head;while(fast != null && fast.next != null){ slow = slow.next; fast = fast.next.next; if(slow == fast){ return true; }}return false;🧩 TEMPLATE 2: Find Cycle StartListNode slow = head;ListNode fast = head;while(fast != null && fast.next != null){ slow = slow.next; fast = fast.next.next; if(slow == fast){ slow = head; while(slow != fast){ slow = slow.next; fast = fast.next; } return slow; }}return null;🧩 TEMPLATE 3: Find Middle of Linked List❓ ProblemFind the middle node of a linked list.🧠 IntuitionFast moves twice as fast:When fast reaches end → slow reaches half👉 Slow = middle💻 CodeListNode slow = head;ListNode fast = head;while(fast != null && fast.next != null){ slow = slow.next; fast = fast.next.next;}return slow;⚠️ Even Length Case1 → 2 → 3 → 4 → 5 → 6👉 Returns 4 (second middle)❓ How to Get First Middle?while(fast.next != null && fast.next.next != null){ slow = slow.next; fast = fast.next.next;}return slow;🧩 Where Else This Technique Is Used?Detect cycleFind cycle startFind middle nodeCheck palindrome (linked list)Split list (merge sort)Intersection problems⚙️ Time & Space ComplexityTime: O(n)Space: O(1)❌ Common MistakesForgetting fast.next != nullThinking meeting point = cycle start ❌Not resetting pointer properly🧠 Final Mental ModelThink in 3 steps:1. Speed DifferenceFast moves faster → gap reduces2. Circular NatureCycle → repeated positions3. Guaranteed MeetingFinite nodes + relative motion → collision🔥 One Line to RememberFast catches slow because it reduces the gap inside a loop.🚀 ConclusionNow you understand:✅ Why fast moves faster✅ Why they meet✅ Why meeting proves cycle✅ Why reset gives cycle start✅ How to find middle using same logic👉 This is not just a trick…It’s a mathematical guarantee based on motion and cycles.💡 Master this once, and you’ll solve multiple linked list problems easily.