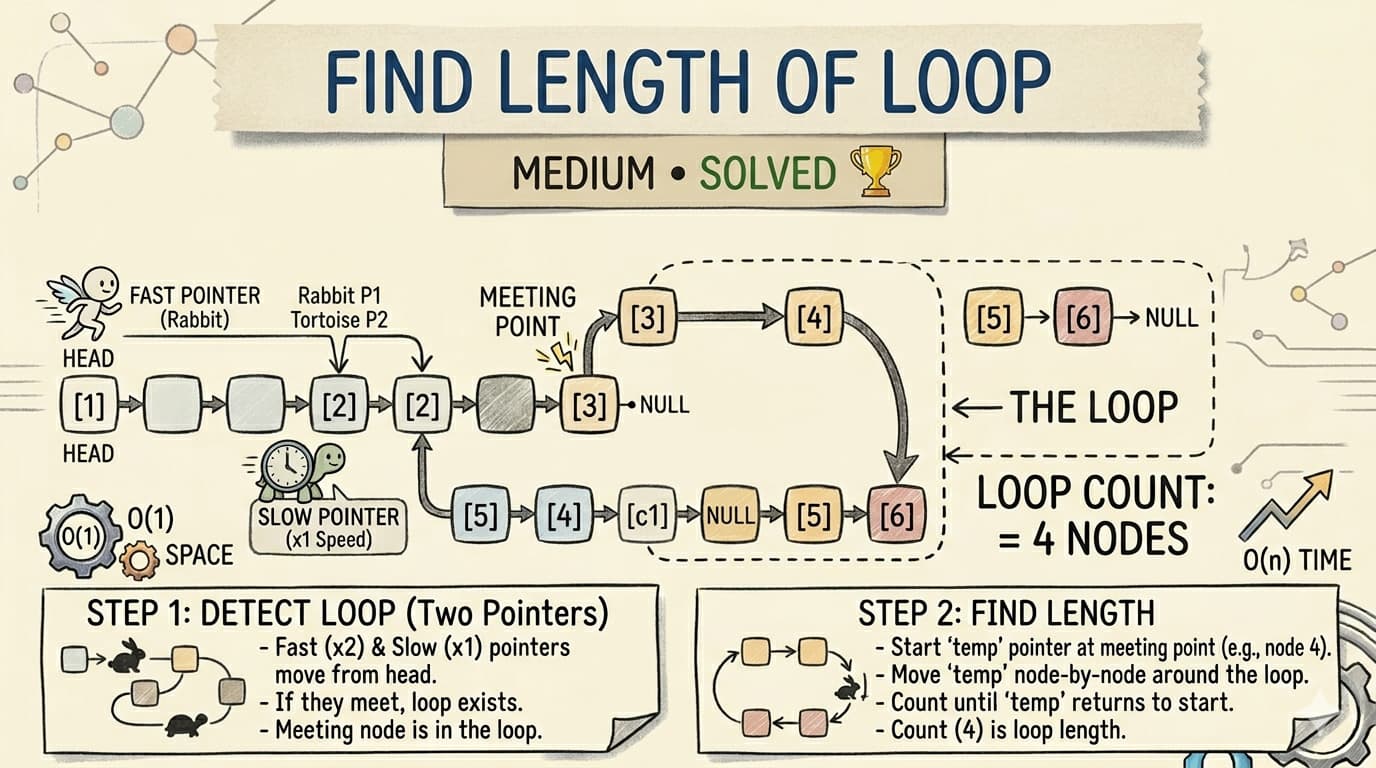
LeetCode 1855 Maximum Distance Between Pair of Values | Two Pointer Java Solution
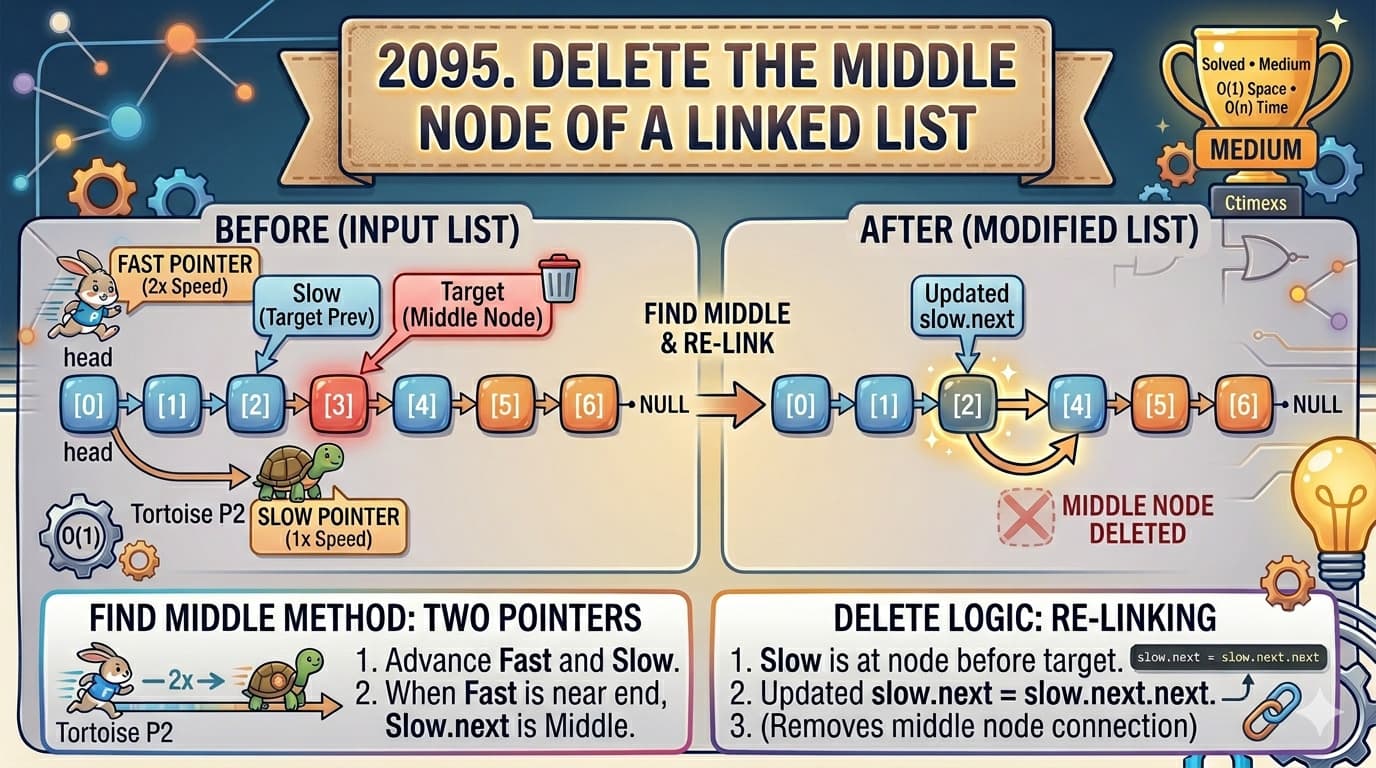
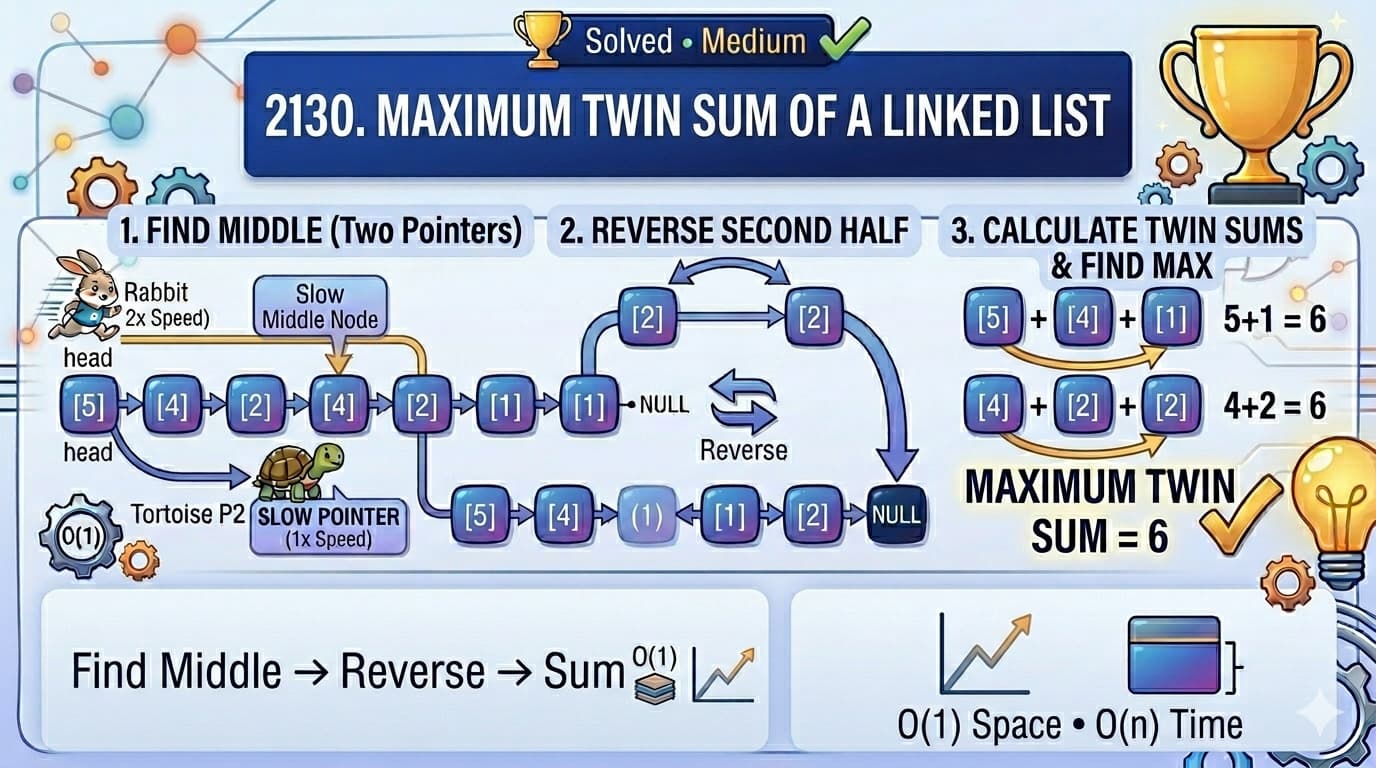
IntroductionLeetCode 1855 – Maximum Distance Between a Pair of Values is a classic problem that beautifully demonstrates the power of the Two Pointer technique on sorted (non-increasing) arrays.At first glance, it may feel like a brute-force problem—but using the right observation, it can be solved efficiently in O(n) time.In this article, we will cover:Problem intuitionWhy brute force failsOptimized two-pointer approach (your solution)Alternative approachesTime complexity analysis🔗 Problem LinkLeetCode: Maximum Distance Between a Pair of ValuesProblem StatementYou are given two non-increasing arrays:nums1nums2A pair (i, j) is valid if:i <= jnums1[i] <= nums2[j]👉 Distance = j - iReturn the maximum distance among all valid pairs.ExamplesExample 1Input:nums1 = [55,30,5,4,2]nums2 = [100,20,10,10,5]Output:2Key InsightThe most important observation:Both arrays are NON-INCREASING👉 This allows us to use two pointers efficiently instead of brute force.❌ Naive Approach (Brute Force)IdeaTry all (i, j) pairsCheck conditionsTrack maximumComplexityTime: O(n × m) ❌👉 This will cause TLE for large inputs (up to 10⁵)✅ Optimized Approach: Two PointersIntuitionUse two pointers:i → nums1j → nums2We try to:Expand j as far as possibleMove i only when necessaryKey LogicIf nums1[i] <= nums2[j] → valid → increase jElse → move i forwardJava Codeclass Solution { public int maxDistance(int[] nums1, int[] nums2) { int i = 0; // pointer for nums1 int j = 0; // pointer for nums2 int max = Integer.MIN_VALUE; // Traverse both arrays while (i < nums1.length && j < nums2.length) { // Valid pair condition if (nums1[i] <= nums2[j] && i <= j) { // Update maximum distance max = Math.max(max, j - i); // Try to expand distance by moving j j++; } else if (nums1[i] >= nums2[j]) { // nums1[i] is too large → move i forward i++; } else { // Just move j forward j++; } } // If no valid pair found, return 0 return max == Integer.MIN_VALUE ? 0 : max; }}Step-by-Step Dry RunInput:nums1 = [55,30,5,4,2]nums2 = [100,20,10,10,5]Execution:(0,0) → valid → distance = 0Move j → (0,1) → invalid → move iContinue...Final best pair:(i = 2, j = 4) → distance = 2Why This WorksArrays are sorted (non-increasing)Moving j increases distanceMoving i helps find valid pairs👉 No need to re-check previous elementsComplexity AnalysisTime ComplexityO(n + m)Each pointer moves at most once through the array.Space ComplexityO(1) (no extra space used)Alternative Approach: Binary SearchIdeaFor each i in nums1:Use binary search in nums2Find farthest j such that:nums2[j] >= nums1[i]ComplexityO(n log m)Code (Binary Search Approach)class Solution { public int maxDistance(int[] nums1, int[] nums2) { int max = 0; for (int i = 0; i < nums1.length; i++) { int left = i, right = nums2.length - 1; while (left <= right) { int mid = left + (right - left) / 2; if (nums2[mid] >= nums1[i]) { max = Math.max(max, mid - i); left = mid + 1; } else { right = mid - 1; } } } return max; }}Two Pointer vs Binary SearchApproachTimeSpaceTwo PointerO(n + m) ✅O(1)Binary SearchO(n log m)O(1)👉 Two pointer is optimal hereKey TakeawaysUse two pointers when arrays are sortedAlways look for monotonic propertiesAvoid brute force when constraints are largeGreedy pointer movement can optimize drasticallyCommon Interview PatternsThis problem is related to:Two pointer problemsSliding windowBinary search on arraysGreedy expansionConclusionThe Maximum Distance Between a Pair of Values problem is a great example of how recognizing array properties can drastically simplify the solution.By using the two-pointer technique, we reduce complexity from O(n²) to O(n)—a massive improvement.Frequently Asked Questions (FAQs)1. Why do we use two pointers?Because arrays are sorted, allowing linear traversal.2. Why not brute force?It is too slow for large inputs (10⁵).3. What is the best approach?👉 Two-pointer approach