Sort a Stack Using Recursion - Java Solution Explained
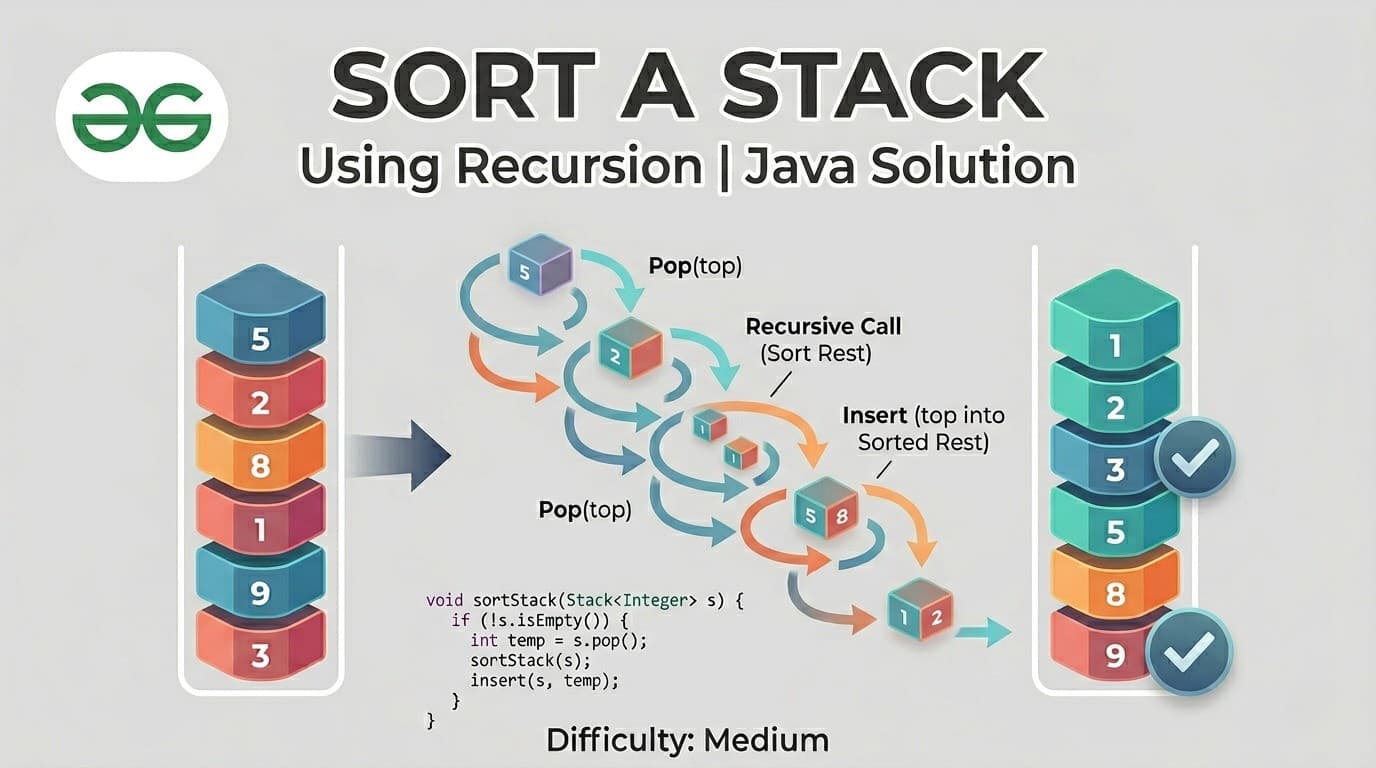
IntroductionSort a Stack is one of those problems that feels impossible at first — you only have access to the top of a stack, you cannot index into it, and the only tools you have are push, pop, and peek. How do you sort something with such limited access?The answer is recursion. And this problem is a perfect example of how recursion can do something elegant that feels like it should require much more complex logic.You can find this problem here — Sort a Stack — GeeksForGeeksThis article explains the complete intuition, both recursive functions in detail, a thorough dry run, all approaches, and complexity analysis.What Is the Problem Really Asking?You have a stack of integers. Sort it so that the smallest element is at the bottom and the largest element is at the top.Input: [41, 3, 32, 2, 11] (11 is at top)Output: [41, 32, 11, 3, 2] (2 is at top, 41 at bottom)Wait — if smallest is at bottom and largest at top, then popping gives you the smallest first. So the stack is sorted in ascending order from top to bottom when you pop.The constraints make this interesting — you can only use stack operations (push, pop, peek, isEmpty). No arrays, no sorting algorithms directly on the data, no random access.Real Life Analogy — Sorting a Stack of BooksImagine a stack of books of different thicknesses on your desk. You want the thinnest book on top and thickest at the bottom. But you can only take from the top.Here is what you do — pick up books one by one from the top and set them aside. Once you have removed enough, place each book back in its correct position. If the book you are placing is thicker than what is currently on top, slide the top books aside temporarily, place the thick book down, then put the others back.That is exactly what the recursive sort does — take elements out one by one, and insert each back into the correct position.The Core Idea — Two Recursive Functions Working TogetherThe solution uses two recursive functions that work hand in hand:sortStack(st) — removes elements one by one until the stack is empty, then inserts each back using insertinsert(st, temp) — inserts a single element into its correct sorted position in an already-sorted stackThink of it like this — sortStack is the manager that empties the stack recursively, and insert is the worker that places each element in the right position on the way back.Function 1: sortStack — The Main Recursive Driverpublic void sortStack(Stack<Integer> st) { // base case — empty or single element is already sorted if (st.empty() || st.size() == 1) return; // Step 1: remove the top element int temp = st.pop(); // Step 2: recursively sort the remaining stack sortStack(st); // Step 3: insert the removed element in correct position insert(st, temp);}How to Think About ThisThe leap of faith here — trust that sortStack correctly sorts whatever is below. After the recursive call, the remaining stack is perfectly sorted. Now your only job is to insert temp (the element you removed) into its correct position in that sorted stack.This is the classic "solve smaller, fix current" recursion pattern. Reduce the problem by one element, trust recursion for the rest, then fix the current element's position.Function 2: insert — Placing an Element in Sorted Positionvoid insert(Stack<Integer> st, int temp) { // base case 1: stack is empty — just push // base case 2: top element is smaller or equal — push on top if (st.empty() || st.peek() <= temp) { st.push(temp); return; } // top element is greater than temp // temp needs to go below the top element int val = st.pop(); // temporarily remove the top insert(st, temp); // try inserting temp deeper st.push(val); // restore the removed element on top}How to Think About ThisYou want to insert temp in sorted order. The stack is already sorted (largest on top). So:If the top is smaller than or equal to temp → temp belongs on top. Push it.If the top is greater than temp → temp needs to go below the top. So pop the top temporarily, try inserting temp deeper, then push the top back.This is the same "pop, recurse deeper, push back" pattern you saw in the Baseball Game problem — when you need to access elements below the top without permanent removal.Complete Solutionclass Solution { // insert temp into its correct position in sorted stack void insert(Stack<Integer> st, int temp) { if (st.empty() || st.peek() <= temp) { st.push(temp); return; } int val = st.pop(); insert(st, temp); st.push(val); } // sort the stack using recursion public void sortStack(Stack<Integer> st) { if (st.empty() || st.size() == 1) return; int temp = st.pop(); // remove top sortStack(st); // sort remaining insert(st, temp); // insert top in correct position }}Detailed Dry Run — st = [3, 2, 1] (1 at top)Let us trace every single call carefully.sortStack calls (going in):sortStack([3, 2, 1]) temp = 1, remaining = [3, 2] call sortStack([3, 2]) temp = 2, remaining = [3] call sortStack([3]) size == 1, return ← base case now insert(st=[3], temp=2) peek=3 > 2, pop val=3 insert(st=[], temp=2) st empty, push 2 ← base case push val=3 back stack is now [2, 3] (3 on top) sortStack([3,2]) done → stack = [2, 3] now insert(st=[2,3], temp=1) peek=3 > 1, pop val=3 insert(st=[2], temp=1) peek=2 > 1, pop val=2 insert(st=[], temp=1) st empty, push 1 ← base case push val=2 back stack = [1, 2] push val=3 back stack = [1, 2, 3] (3 on top)sortStack done → stack = [1, 2, 3]✅ Final stack (3 on top, 1 at bottom): largest at top, smallest at bottom — correctly sorted!Detailed Dry Run — st = [41, 3, 32, 2, 11] (11 at top)Let us trace at a higher level to see the pattern:sortStack calls unwinding (popping phase):sortStack([41, 3, 32, 2, 11]) pop 11, sortStack([41, 3, 32, 2]) pop 2, sortStack([41, 3, 32]) pop 32, sortStack([41, 3]) pop 3, sortStack([41]) base case — return insert([41], 3) → [3, 41] (41 on top) insert([3, 41], 32) → [3, 32, 41] (41 on top) insert([3, 32, 41], 2) → [2, 3, 32, 41] (41 on top) insert([2, 3, 32, 41], 11) → [2, 3, 11, 32, 41] (41 on top)✅ Final: [2, 3, 11, 32, 41] with 41 at top, 2 at bottom — correct!Let us verify the insert([3, 32, 41], 2) step in detail since it involves multiple pops:insert(st=[3, 32, 41], temp=2) peek=41 > 2, pop val=41 insert(st=[3, 32], temp=2) peek=32 > 2, pop val=32 insert(st=[3], temp=2) peek=3 > 2, pop val=3 insert(st=[], temp=2) st empty, push 2 push val=3 back → [2, 3] push val=32 back → [2, 3, 32] push val=41 back → [2, 3, 32, 41]Beautiful chain of pops followed by a chain of pushes — recursion handling what would be very messy iterative logic.Approach 2: Using an Additional Stack (Iterative)If recursion is not allowed or you want an iterative solution, you can use a second stack.public void sortStack(Stack<Integer> st) { Stack<Integer> tempStack = new Stack<>(); while (!st.empty()) { int curr = st.pop(); // move elements from tempStack back to st // until we find the right position for curr while (!tempStack.empty() && tempStack.peek() > curr) { st.push(tempStack.pop()); } tempStack.push(curr); } // move everything back to original stack while (!tempStack.empty()) { st.push(tempStack.pop()); }}How This WorkstempStack is maintained in sorted order (smallest on top). For each element popped from st, we move elements from tempStack back to st until we find the right position, then push. At the end, transfer everything back.Time Complexity: O(n²) — same as recursive approach Space Complexity: O(n) — explicit extra stackApproach 3: Using Collections.sort (Cheat — Not Recommended)public void sortStack(Stack<Integer> st) { List<Integer> list = new ArrayList<>(st); Collections.sort(list); // ascending st.clear(); for (int num : list) { st.push(num); // smallest pushed first = smallest at bottom }}This gives the right answer but completely defeats the purpose of the problem. Never use this in an interview — it shows you do not understand the problem's intent.Time Complexity: O(n log n) Space Complexity: O(n)Approach ComparisonApproachTimeSpaceAllowed in InterviewCode ComplexityRecursive (Two Functions)O(n²)O(n)✅ Best answerMediumIterative (Two Stacks)O(n²)O(n)✅ Good alternativeMediumCollections.sortO(n log n)O(n)❌ Defeats purposeEasyTime and Space Complexity AnalysisRecursive ApproachTime Complexity: O(n²)For each of the n elements popped by sortStack, the insert function may traverse the entire stack to find the correct position — O(n) per insert. Total: O(n) × O(n) = O(n²).This is similar to insertion sort — and in fact, this recursive approach IS essentially insertion sort implemented on a stack using recursion.Space Complexity: O(n)No extra data structure is used. But the call stack holds up to n frames for sortStack and up to n additional frames for insert. In the worst case, total recursion depth is O(n) + O(n) = O(n) space.The Connection to Insertion SortIf you have studied sorting algorithms, this solution will look very familiar. It is Insertion Sort implemented recursively on a stack:sortStack is like the outer loop — take one element at a timeinsert is like the inner loop — find the correct position by comparing and shiftingThe key difference from array-based insertion sort is that "shifting" in an array is done by moving elements right. Here, "shifting" is done by temporarily popping elements off the stack, inserting at the right depth, then pushing back. Recursion handles the "shift" naturally.Common Mistakes to AvoidWrong base case in insert The base case is st.empty() || st.peek() <= temp. Both conditions are needed. Without st.empty(), you call peek() on an empty stack and get an exception. Without st.peek() <= temp, you never stop even when you find the right position.Using < instead of <= in insert Using strictly less than means equal elements get treated as "wrong position" and cause unnecessary recursion. Using <= correctly handles duplicates — equal elements stay in their current relative order.Calling sortStack instead of insert inside insert insert should only call itself recursively. Calling sortStack inside insert re-sorts an already-sorted stack — completely wrong and causes incorrect results.Not pushing val back after the recursive insert call This is the most common bug. After insert(st, temp) places temp in the correct position, you must push val back on top. Forgetting this loses elements from the stack permanently.FAQs — People Also AskQ1. How do you sort a stack without using extra space in Java? Using recursion — the call stack itself serves as temporary storage. sortStack removes elements one by one and insert places each back in its correct sorted position. No explicit extra data structure is needed, but O(n) implicit call stack space is used.Q2. What is the time complexity of sorting a stack using recursion? O(n²) in all cases — for each of the n elements, the insert function traverses up to n elements to find the correct position. This is equivalent to insertion sort applied to a stack.Q3. Can you sort a stack without recursion? Yes — using a second auxiliary stack. Pop elements from the original stack one by one and insert each into the correct position in the second stack by temporarily moving elements back. Transfer everything back to the original stack at the end.Q4. Why does the insert function need to push val back after the recursive call? Because the goal of insert is to place temp in the correct position WITHOUT losing any existing elements. When we pop val temporarily to go deeper, we must restore it after temp has been placed. Not restoring it means permanently losing that element from the stack.Q5. Is sorting a stack asked in coding interviews? Yes, it appears frequently at companies like Amazon, Adobe, and in platforms like GeeksForGeeks and InterviewBit. It tests whether you understand recursion deeply enough to use it as a mechanism for reordering — not just for computation.Similar Problems to Practice NextDelete Middle Element of a Stack — use same recursive pop-recurse-push patternReverse a Stack — very similar recursive approach, great warmup84. Largest Rectangle in Histogram — advanced stack problem946. Validate Stack Sequences — stack simulation150. Evaluate Reverse Polish Notation — stack with operationsConclusionSort a Stack Using Recursion is a beautiful problem that demonstrates the true power of recursion — using the call stack itself as temporary storage to perform operations that would otherwise require extra data structures.The key insight is splitting the problem into two clean responsibilities. sortStack handles one job — peel elements off one by one until the base case, then trigger insert on the way back up. insert handles one job — place a single element into its correct position in an already-sorted stack by temporarily moving larger elements aside.Once you see those two responsibilities clearly, the code almost writes itself. And once this pattern clicks, it directly prepares you for more advanced recursive problems like reversing a stack, deleting the middle element, and even understanding how recursive backtracking works at a deeper level.