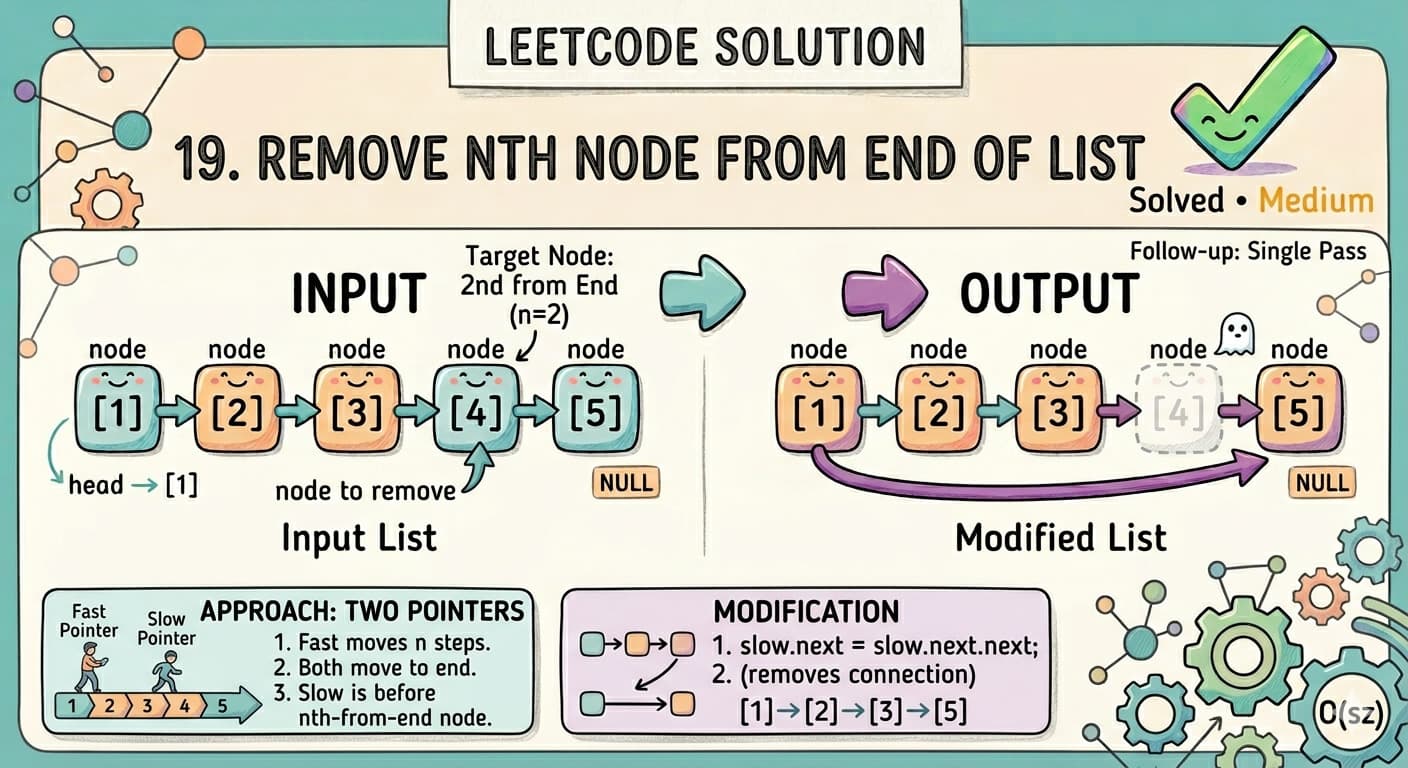
Remove Nth Node From End – The Smart Way to Solve in One Pass (LeetCode 19)
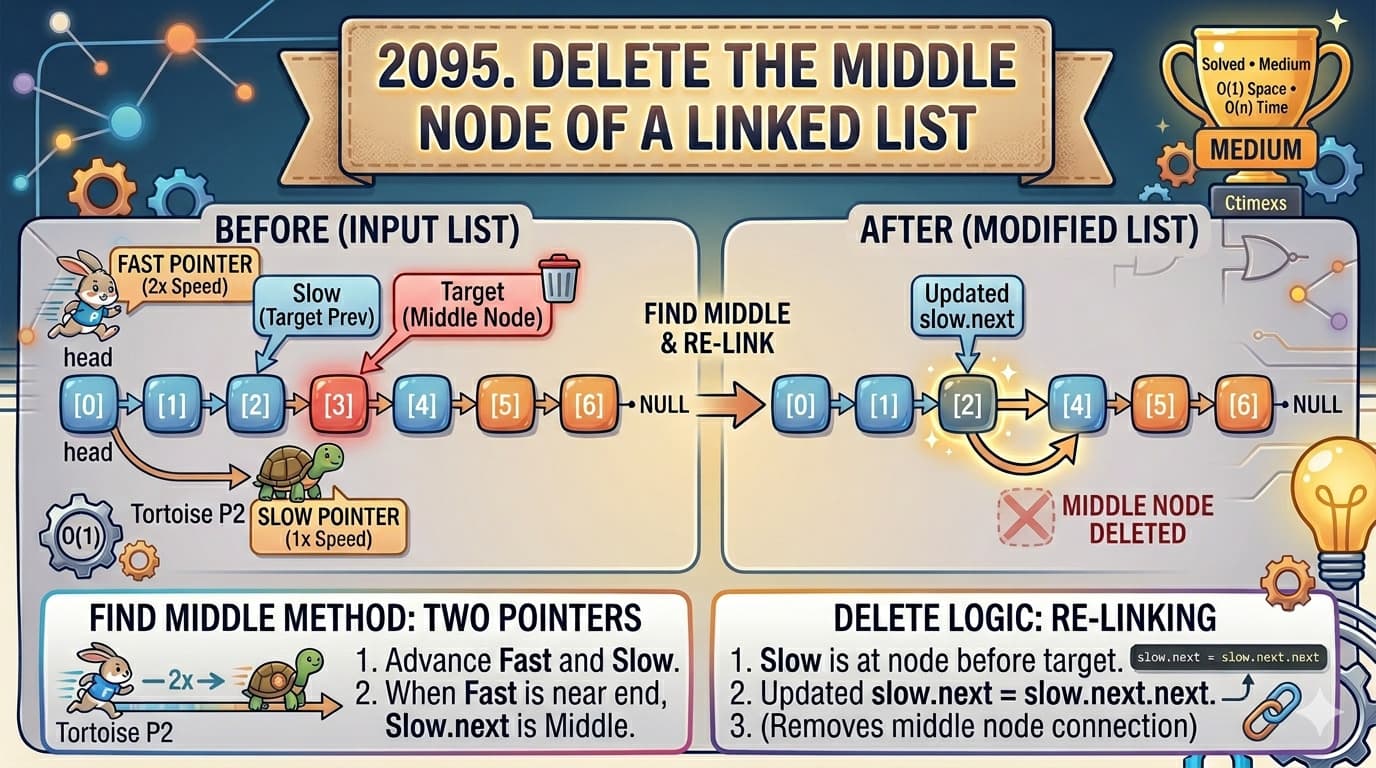
🚀 Try the ProblemPractice here:https://leetcode.com/problems/remove-nth-node-from-end-of-list/🤔 Let’s Think Differently…Imagine this list:1 → 2 → 3 → 4 → 5You are asked:👉 Remove the 2nd node from the endSo counting from end:5 (1st), 4 (2nd) ❌ remove thisFinal list:1 → 2 → 3 → 5🧠 Problem in Simple WordsYou are given:Head of a linked listA number n👉 Remove the nth node from the end👉 Return the updated list📦 Constraints1 <= number of nodes <= 300 <= Node.val <= 1001 <= n <= size of list🧩 First Thought (Counting Method)💡 IdeaCount total nodesFind position from start:position = total - nTraverse again and remove that node✅ Code (Counting Approach)class Solution { public ListNode removeNthFromEnd(ListNode head, int n) { if(head == null) return head; // Step 1: Count nodes int co = 0; ListNode tempHead = head; while(tempHead != null){ co++; tempHead = tempHead.next; } // Step 2: If removing head if(co == n) return head.next; // Step 3: Find node before target int k = co - n; int con = 1; ListNode temp = head; while(con < k){ temp = temp.next; con++; } // Step 4: Remove node temp.next = temp.next.next; return head; }}⏱️ ComplexityTime ComplexityO(n) + O(n) = O(n)(two traversals)Space ComplexityO(1)⚠️ Limitation of This Approach👉 It requires two passesBut the problem asks:Can you solve it in one pass?🚀 Optimal Approach: Two Pointer Technique (One Pass)Now comes the interesting part 🔥🧠 Core IdeaWe use two pointers:fast pointerslow pointer🎯 Trick👉 Move fast pointer n steps aheadThen move both pointers together until:fast reaches endAt that moment:👉 slow will be at the node before the one to remove📌 Why This WorksBecause the gap between fast and slow is always n nodesSo when fast reaches end:👉 slow is exactly where we need it🔥 Step-by-Step VisualizationList:1 → 2 → 3 → 4 → 5n = 2Step 1: Move fast 2 stepsfast → 3slow → 1Step 2: Move both togetherfast → 4, slow → 2fast → 5, slow → 3fast → null, slow → 4👉 Now slow is at node before target🧼 Clean and Safe Approach (Using Dummy Node)Using dummy node avoids edge cases like removing head.💻 Code (Optimal One Pass Solution)class Solution { public ListNode removeNthFromEnd(ListNode head, int n) { // Dummy node to handle edge cases ListNode dummy = new ListNode(0, head); ListNode fast = dummy; ListNode slow = dummy; // Move fast pointer n steps ahead for(int i = 0; i < n; i++){ fast = fast.next; } // Move both pointers while(fast.next != null){ fast = fast.next; slow = slow.next; } // Remove nth node slow.next = slow.next.next; return dummy.next; }}⏱️ ComplexityTime ComplexityO(n)(single pass)Space ComplexityO(1)⚖️ Comparing ApproachesApproachPassesTimeSpaceDifficultyCounting2O(n)O(1)EasyTwo Pointer1O(n)O(1)Optimal❌ Common MistakesForgetting to handle removing head nodeNot using dummy nodeOff-by-one errors in pointer movementMoving fast incorrectly🔥 Interview InsightThis problem is a classic example of:Fast & Slow Pointer TechniqueUsed in many problems like:Cycle DetectionMiddle of Linked ListPalindrome Linked List🧠 Final ThoughtAt first, counting feels natural…But once you learn this trick:"Create a gap and move together"👉 You unlock a powerful pattern.🚀 ConclusionThe Remove Nth Node From End problem is not just about deletion…It teaches:Efficient traversalPointer coordinationOne-pass optimization👉 Tip: Whenever you see “from end”, think:"Can I use two pointers with a gap?"That’s your shortcut to solving these problems like a pro 🚀