LeetCode 143 Reorder List - Java Solution Explained
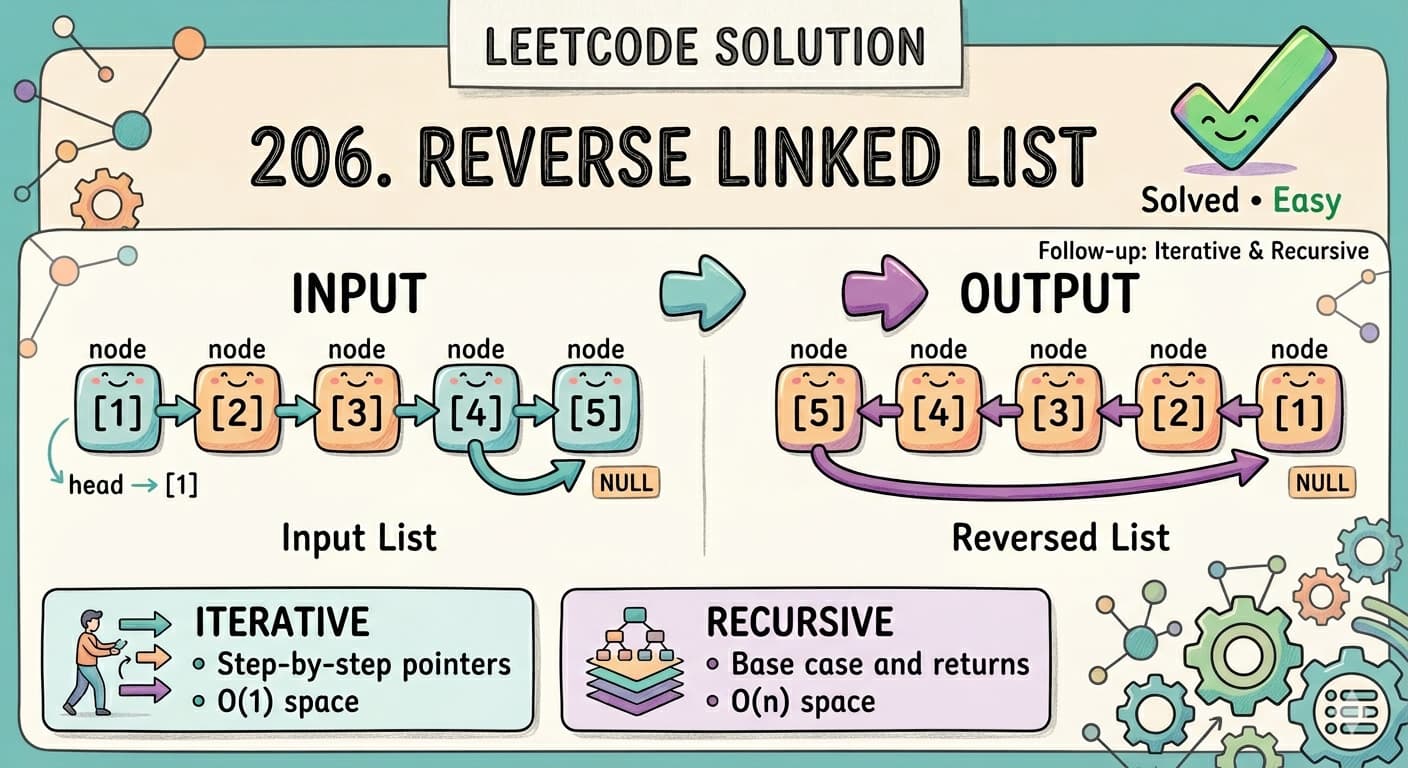
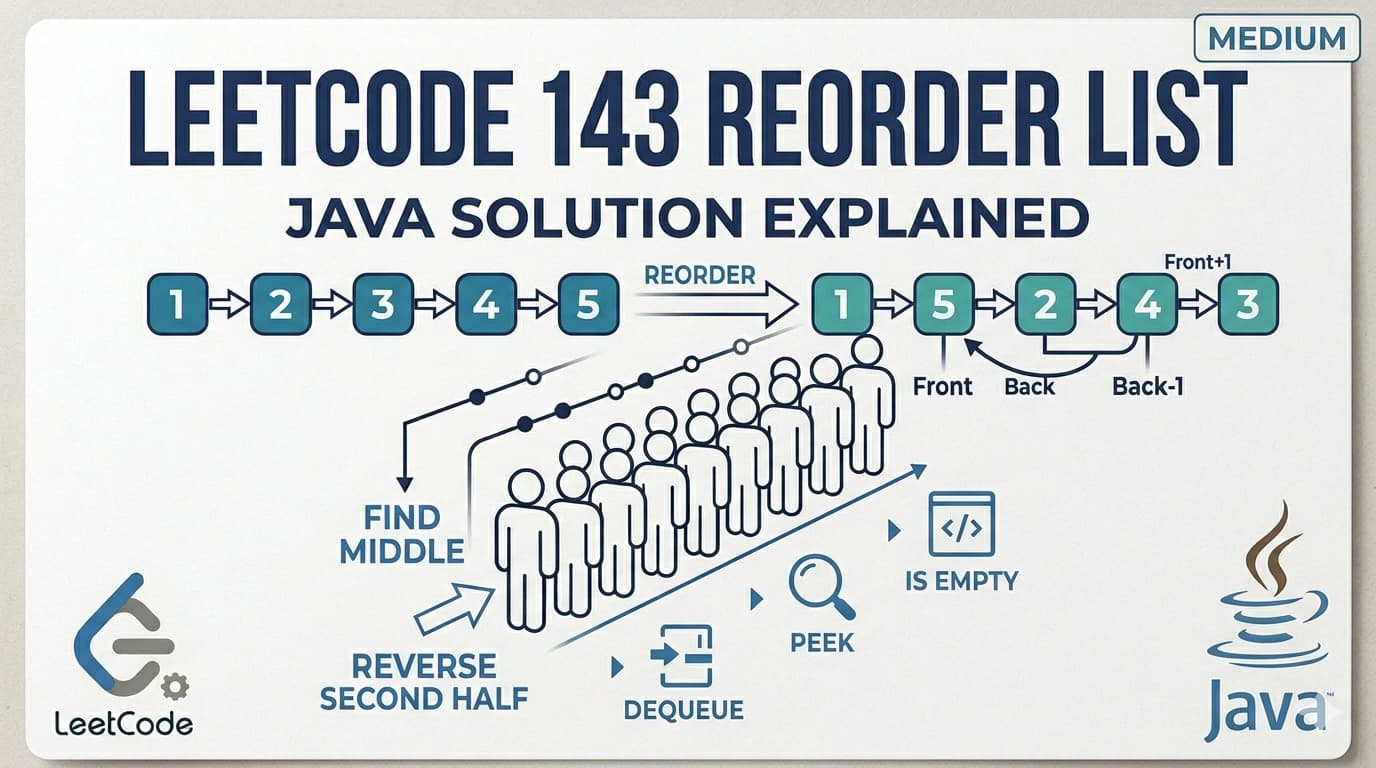
IntroductionLeetCode 143 Reorder List is one of those problems that looks simple when you read it but immediately makes you wonder — where do I even start? There is no single trick that solves it. Instead it combines three separate linked list techniques into one clean solution. Mastering this problem means you have genuinely understood linked lists at an intermediate level.You can find the problem here — LeetCode 143 Reorder List.This article walks through everything — what the problem wants, the intuition behind each step, all three techniques used, a detailed dry run, complexity analysis, and common mistakes beginners make.What Is the Problem Really Asking?You have a linked list: L0 → L1 → L2 → ... → LnYou need to reorder it to: L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → ...In plain English — take one node from the front, then one from the back, then one from the front, then one from the back, and keep alternating until all nodes are used.Example:Input: 1 → 2 → 3 → 4 → 5Output: 1 → 5 → 2 → 4 → 3Node 1 from front, Node 5 from back, Node 2 from front, Node 4 from back, Node 3 stays in middle.Real Life Analogy — Dealing Cards From Both EndsImagine you have a deck of cards laid out in a line face up: 1, 2, 3, 4, 5. Now you deal them by alternately picking from the left end and the right end of the line:Pick 1 from left → placePick 5 from right → place after 1Pick 2 from left → place after 5Pick 4 from right → place after 2Pick 3 (only one left) → place after 4Result: 1, 5, 2, 4, 3That is exactly what the problem wants. The challenge is doing this efficiently on a singly linked list where you cannot just index from the back.Why This Problem Is Hard for BeginnersIn an array you can just use two pointers — one at the start and one at the end — and swap/interleave easily. But a singly linked list only goes forward. You cannot go backwards. You cannot easily access the last element.This is why the problem requires a three-step approach that cleverly works around the limitations of a singly linked list.The Three Step ApproachEvery experienced developer solves this problem in exactly three steps:Step 1 — Find the middle of the linked list using the Fast & Slow Pointer techniqueStep 2 — Reverse the second half of the linked listStep 3 — Merge the two halves by alternating nodes from eachLet us understand each step deeply before looking at code.Step 1: Finding the Middle — Fast & Slow PointerThe Fast & Slow Pointer technique (also called Floyd's algorithm) uses two pointers moving at different speeds through the list:slow moves one step at a timefast moves two steps at a timeWhen fast reaches the end, slow is exactly at the middle. This works because fast covers twice the distance of slow in the same number of steps.ListNode fast = head;ListNode slow = head;while (fast.next != null && fast.next.next != null) { fast = fast.next.next; slow = slow.next;}// slow is now at the middleFor 1 → 2 → 3 → 4 → 5:Start: slow=1, fast=1Step 1: slow=2, fast=3Step 2: slow=3, fast=5 (fast.next is null, stop)Middle is node 3For 1 → 2 → 3 → 4:Start: slow=1, fast=1Step 1: slow=2, fast=3Step 2: fast.next.next is null, stopslow=2, middle is node 2After finding the middle, we cut the list in two by setting slow.next = null. This disconnects the first half from the second half.Step 2: Reversing the Second HalfOnce we have the second half starting from slow.next, we reverse it. After reversal, what was the last node becomes the first — giving us easy access to the back elements of the original list.public ListNode reverse(ListNode head) { ListNode curr = head; ListNode prev = null; while (curr != null) { ListNode next = curr.next; // save next curr.next = prev; // reverse the link prev = curr; // move prev forward curr = next; // move curr forward } return prev; // prev is the new head}For second half 3 → 4 → 5 (from the first example):Reverse → 5 → 4 → 3Now we have:First half: 1 → 2 → 3 (but 3 is the end since we cut at slow)Wait — actually after cutting at slow=3: first half is 1 → 2 → 3, second half reversed is 5 → 4Let us be precise. For 1 → 2 → 3 → 4 → 5, slow stops at 3. slow.next = null cuts to give:First half: 1 → 2 → 3 → nullSecond half before reverse: 4 → 5Second half after reverse: 5 → 4Step 3: Merging Two HalvesNow we have two lists and we merge them by alternately taking one node from each:Take from first half, take from second half, take from first half, take from second half...ListNode orig = head; // pointer for first halfListNode newhead = second; // pointer for reversed second halfwhile (newhead != null) { ListNode temp1 = orig.next; // save next of first half ListNode temp2 = newhead.next; // save next of second half orig.next = newhead; // first → second newhead.next = temp1; // second → next of first orig = temp1; // advance first half pointer newhead = temp2; // advance second half pointer}Why do we loop on newhead != null and not orig != null? Because the second half is always equal to or shorter than the first half (we cut at middle). Once the second half is exhausted, the remaining first half nodes are already in the correct position.Complete Solutionclass Solution { public ListNode reverse(ListNode head) { ListNode curr = head; ListNode prev = null; while (curr != null) { ListNode next = curr.next; curr.next = prev; prev = curr; curr = next; } return prev; } public void reorderList(ListNode head) { // Step 1: Find middle using fast & slow pointer ListNode fast = head; ListNode slow = head; while (fast.next != null && fast.next.next != null) { fast = fast.next.next; slow = slow.next; } // Step 2: Reverse second half ListNode newhead = reverse(slow.next); slow.next = null; // cut the list into two halves // Step 3: Merge two halves alternately ListNode orig = head; while (newhead != null) { ListNode temp1 = orig.next; ListNode temp2 = newhead.next; orig.next = newhead; newhead.next = temp1; orig = temp1; newhead = temp2; } }}Complete Dry Run — head = [1, 2, 3, 4, 5]Step 1: Find MiddleList: 1 → 2 → 3 → 4 → 5Initial: slow=1, fast=1Iteration 1: slow=2, fast=3Iteration 2: fast.next=4, fast.next.next=5 → slow=3, fast=5fast.next is null → stopslow is at node 3Step 2: Cut and ReverseCut: slow.next = nullFirst half: 1 → 2 → 3 → nullSecond half: 4 → 5Reverse second half 4 → 5:prev=null, curr=4 → next=5, 4.next=null, prev=4, curr=5prev=4, curr=5 → next=null, 5.next=4, prev=5, curr=nullReturn prev=5Reversed second half: 5 → 4 → nullStep 3: Mergeorig=1, newhead=5Iteration 1:temp1 = orig.next = 2temp2 = newhead.next = 4orig.next = newhead → 1.next = 5newhead.next = temp1 → 5.next = 2orig = temp1 = 2newhead = temp2 = 4List so far: 1 → 5 → 2 → 3Iteration 2:temp1 = orig.next = 3temp2 = newhead.next = nullorig.next = newhead → 2.next = 4newhead.next = temp1 → 4.next = 3orig = temp1 = 3newhead = temp2 = nullList so far: 1 → 5 → 2 → 4 → 3newhead is null → loop endsFinal result: 1 → 5 → 2 → 4 → 3 ✅Dry Run — head = [1, 2, 3, 4]Step 1: Find MiddleInitial: slow=1, fast=1Iteration 1: slow=2, fast=3fast.next=4, fast.next.next=null → stopslow is at node 2Step 2: Cut and ReverseFirst half: 1 → 2 → nullSecond half: 3 → 4Reversed: 4 → 3 → nullStep 3: Mergeorig=1, newhead=4Iteration 1:temp1=2, temp2=31.next=4, 4.next=2orig=2, newhead=3List: 1 → 4 → 2 → 3Iteration 2:temp1=null (2.next was originally 3 but we cut at slow=2, so 2.next = null... wait)Actually after cutting at slow=2, first half is 1 → 2 → null, so orig when it becomes 2, orig.next = null.temp1 = orig.next = nulltemp2 = newhead.next = null2.next = 3, 3.next = nullorig = null, newhead = nullnewhead is null → stopFinal result: 1 → 4 → 2 → 3 ✅Why slow.next = null Must Come After Saving newheadThis is a subtle but critical ordering detail in the code. Look at this sequence:ListNode newhead = reverse(slow.next); // save reversed second half FIRSTslow.next = null; // THEN cut the listIf you cut first (slow.next = null) and then try to reverse, you lose the reference to the second half entirely because slow.next is already null. Always save the second half reference before cutting.Time and Space ComplexityTime Complexity: O(n) — each of the three steps (find middle, reverse, merge) makes a single pass through the list. Total is 3 passes = O(3n) = O(n).Space Complexity: O(1) — everything is done by rearranging pointers in place. No extra arrays, no recursion stack, no additional data structures. Just a handful of pointer variables.This is the optimal solution — linear time and constant space.Alternative Approach — Using ArrayList (Simpler but O(n) Space)If you find the three-step approach hard to implement under interview pressure, here is a simpler approach using extra space:public void reorderList(ListNode head) { // store all nodes in ArrayList for random access List<ListNode> nodes = new ArrayList<>(); ListNode curr = head; while (curr != null) { nodes.add(curr); curr = curr.next; } int left = 0; int right = nodes.size() - 1; while (left < right) { nodes.get(left).next = nodes.get(right); left++; if (left == right) break; // odd number of nodes nodes.get(right).next = nodes.get(left); right--; } nodes.get(left).next = null; // terminate the list}This is much easier to understand and code. Store all nodes in an ArrayList, use two pointers from both ends, and wire up the next pointers.Time Complexity: O(n) Space Complexity: O(n) — ArrayList stores all nodesThis is acceptable in most interviews. Mention the O(1) space approach as the optimal solution if asked.Common Mistakes to AvoidNot cutting the list before merging If you do not set slow.next = null after finding the middle, the first half still points into the second half. During merging, this creates cycles and infinite loops. Always cut before merging.Wrong loop condition for finding the middle The condition fast.next != null && fast.next.next != null ensures fast does not go out of bounds when jumping two steps. Using just fast != null && fast.next != null moves slow one step too far for even-length lists.Looping on orig instead of newhead The merge loop should run while newhead != null, not while orig != null. The second half is always shorter or equal to the first half. Once the second half is done, the remaining first half is already correctly placed.Forgetting to save both temp pointers before rewiring In the merge step, you must save both orig.next and newhead.next before changing any pointers. Changing orig.next first and then trying to access orig.next to save it gives you the wrong node.How This Problem Combines Multiple PatternsThis problem is special because it does not rely on a single technique. It is a combination of three fundamental linked list operations:Fast & Slow Pointer — you saw this concept in problems like finding the middle of a list and detecting cycles (LeetCode 141, 142).Reverse a Linked List — the most fundamental linked list operation, appears in LeetCode 206 and as a subtask in dozens of problems.Merge Two Lists — similar to merging two sorted lists (LeetCode 21) but here order is not sorted, it is alternating.Solving this problem proves you are comfortable with all three patterns individually and can combine them when needed.FAQs — People Also AskQ1. What is the most efficient approach for LeetCode 143 Reorder List? The three-step approach — find middle with fast/slow pointer, reverse second half, merge alternately — runs in O(n) time and O(1) space. It is the optimal solution. The ArrayList approach is O(n) time and O(n) space but simpler to code.Q2. Why use fast and slow pointer to find the middle? Because a singly linked list has no way to access elements by index. You cannot just do list[length/2]. The fast and slow pointer technique finds the middle in a single pass without knowing the length beforehand.Q3. Why reverse the second half instead of the first half? The problem wants front-to-back alternation. If you reverse the second half, its first node is the original last node — exactly what you need to interleave with the front of the first half. Reversing the first half would give the wrong order.Q4. What is the time complexity of LeetCode 143? O(n) time for three linear passes (find middle, reverse, merge). O(1) space since all operations are in-place pointer manipulations with no extra data structures.Q5. Is LeetCode 143 asked in coding interviews? Yes, frequently at companies like Amazon, Google, Facebook, and Microsoft. It is considered a benchmark problem for linked list mastery because it requires combining three separate techniques cleanly under pressure.Similar LeetCode Problems to Practice Next206. Reverse Linked List — Easy — foundation for step 2 of this problem876. Middle of the Linked List — Easy — fast & slow pointer isolated21. Merge Two Sorted Lists — Easy — merging technique foundation234. Palindrome Linked List — Easy — also uses find middle + reverse second half148. Sort List — Medium — merge sort on linked list, uses same split techniqueConclusionLeetCode 143 Reorder List is one of the best Medium linked list problems because it forces you to think in multiple steps and combine techniques rather than apply a single pattern. The fast/slow pointer finds the middle efficiently without knowing the length. Reversing the second half turns the "cannot go backwards" limitation of singly linked lists into a non-issue. And the alternating merge weaves everything together cleanly.Work through the dry runs carefully — especially the pointer saving step in the merge. Once you see why each step is necessary and how they connect, this problem will always feel approachable no matter when it shows up in an interview.