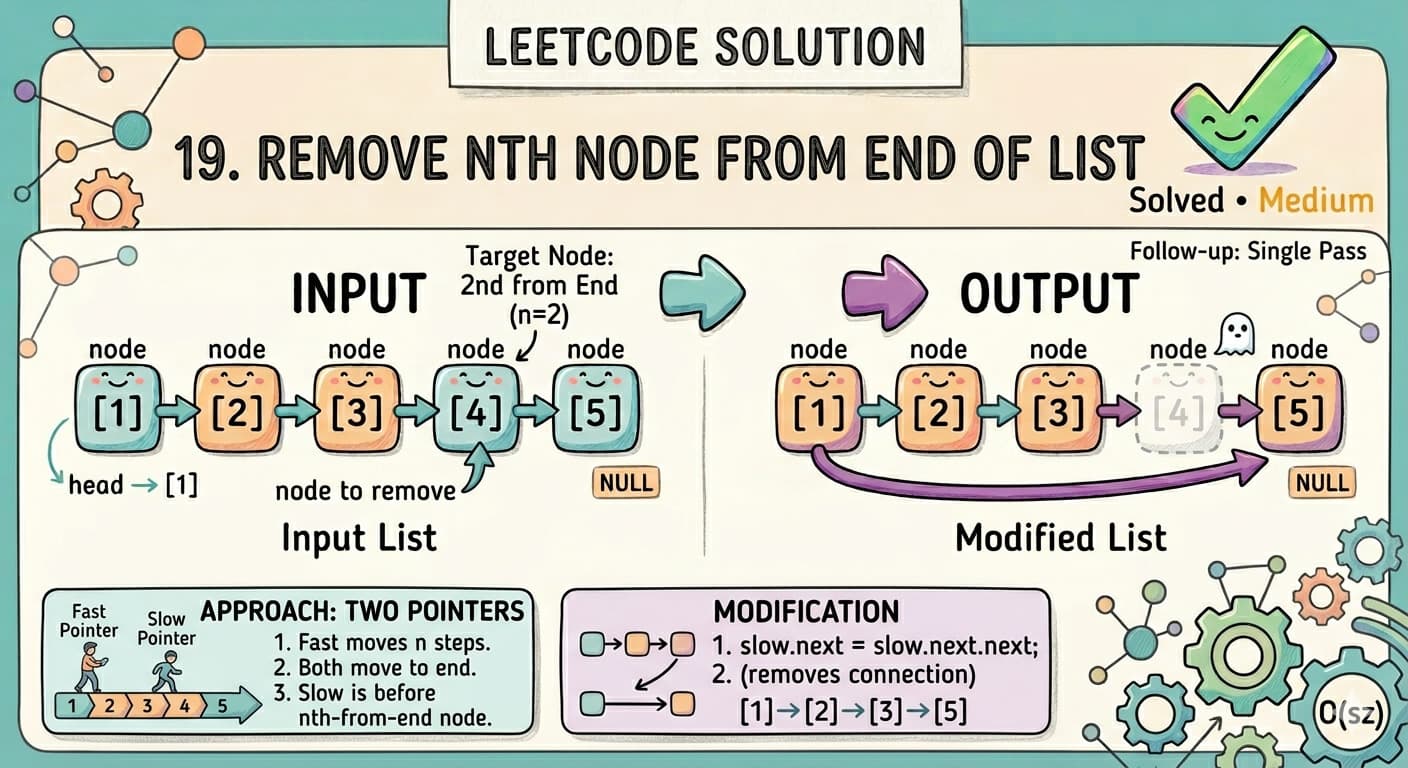
Maximum Product Subarray
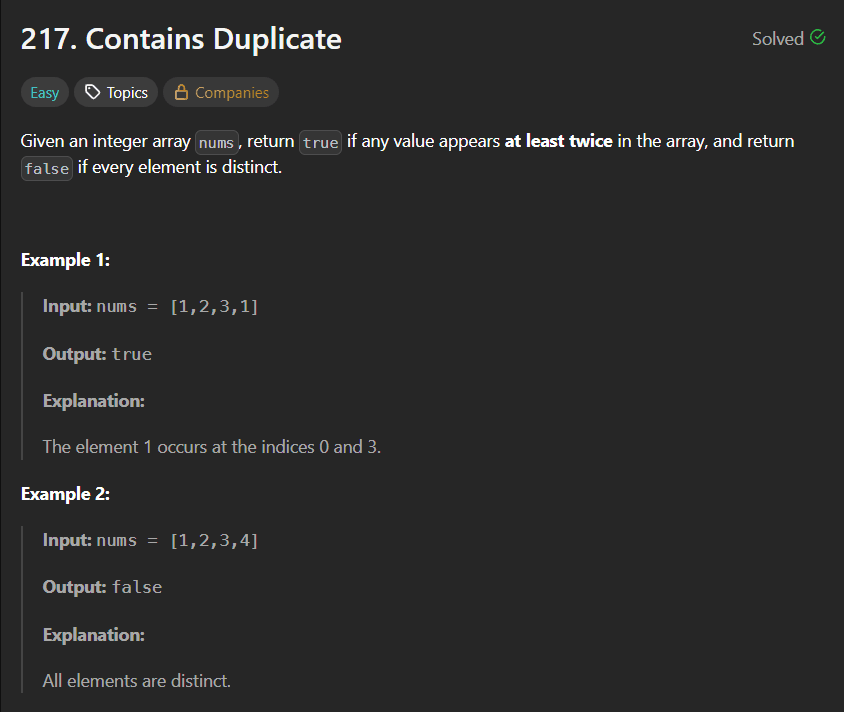
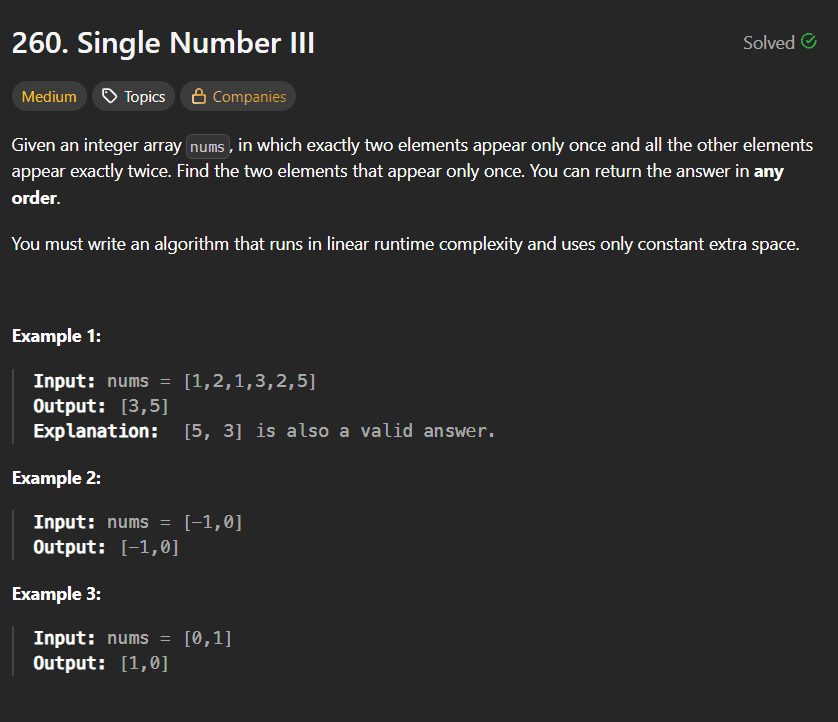
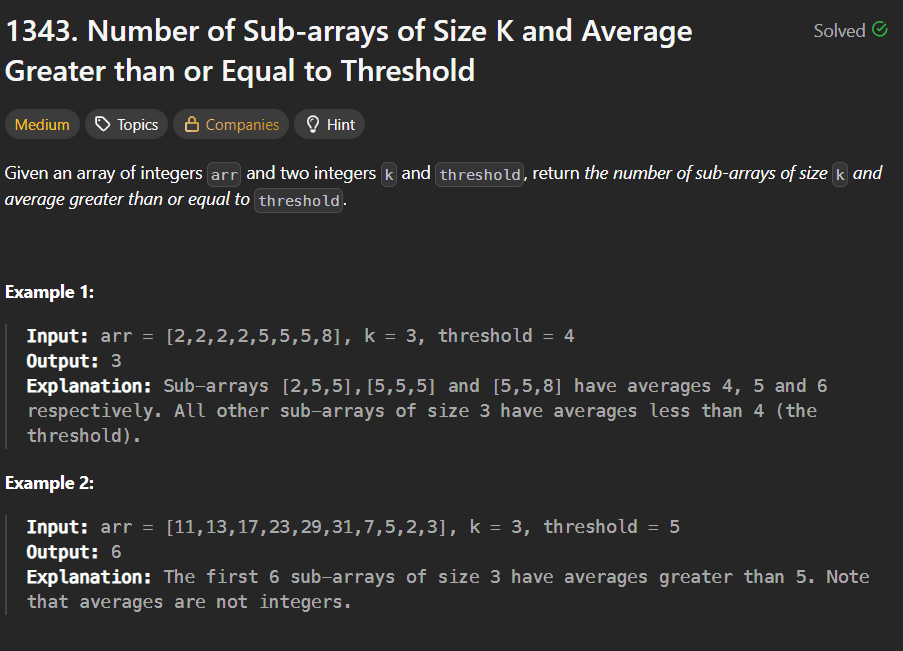
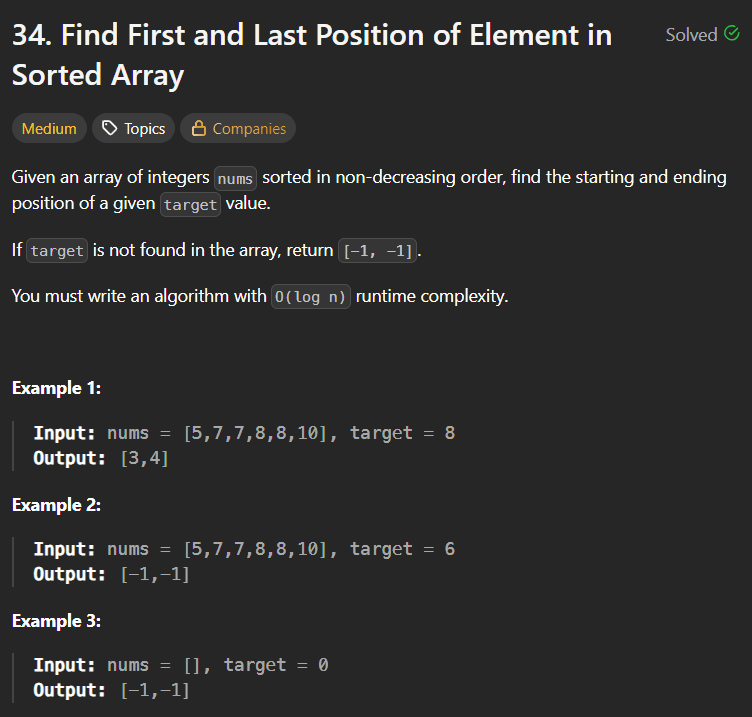
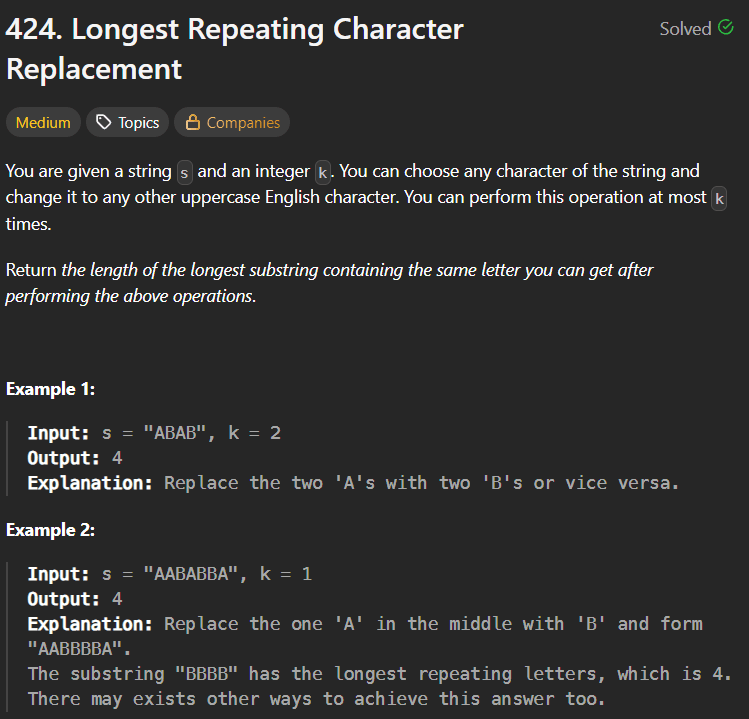
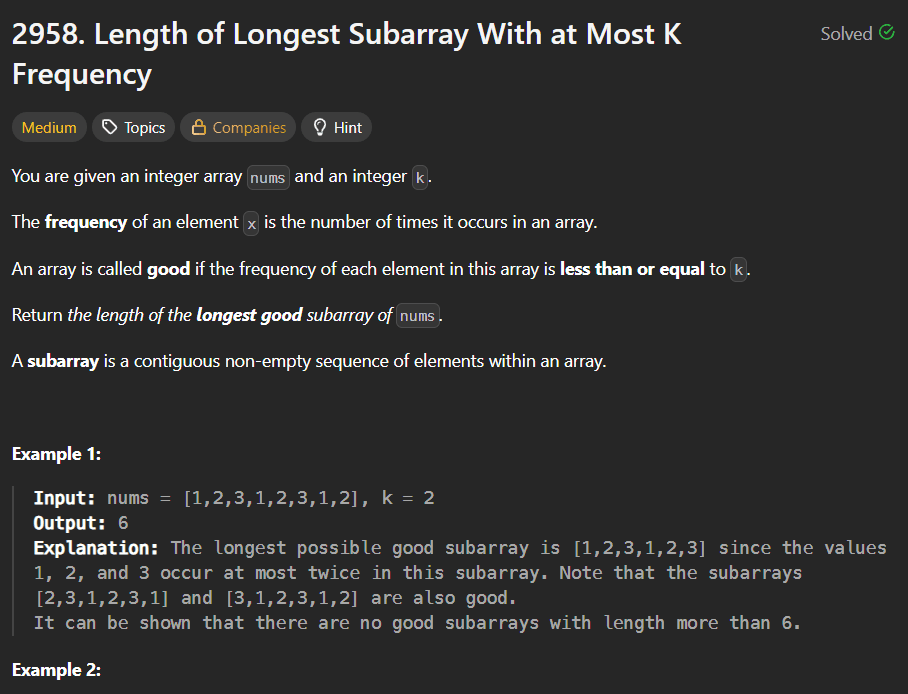
LeetCode Problem 152Link of the Problem to try -: LinkGiven an integer array nums, find a subarray that has the largest product, and return the product.The test cases are generated so that the answer will fit in a 32-bit integer.Note that the product of an array with a single element is the value of that element.Example 1:Input: nums = [2,3,-2,4]Output: 6Explanation: [2,3] has the largest product 6.Example 2:Input: nums = [-2,0,-1]Output: 0Explanation: The result cannot be 2, because [-2,-1] is not a subarray.Constraints:1 <= nums.length <= 2 * 104-10 <= nums[i] <= 10The product of any subarray of nums is guaranteed to fit in a 32-bit integer.Solution:Approach(1)In this approach we have to just multiply all the elements of our array from left to right and right to left also we have to ensure that whenever our multiplication goes to negative it must be reset to 1 so that when next element multiply it not be negative or zero as well due to this approach we will traverse the whole array one time and that's why it's time complexity is O(n).Solution Code:public int maxProduct(int[] nums) {int max =Integer.MIN_VALUE;int l =1;int r =1;int rev = nums.length-1;for(int i =0;i <nums.length;i++){if(l ==0) l =1;if(r ==0) r =1;l*=nums[i];r*=nums[rev];rev--;max = Math.max(max,Math.max(l,r));}return max;}Approach(2)In this approach we will create two variables like currmin and currmax these two variales will be store the maximum multiplied value and the minimum multiply value just the thing we have to handle is that whenever we got a negative value in the arrya we have to interchange the value of both variables because if we got a negative value then if that value multiply by the currmax variable then make it's value minimum as (+ x - = -) that's why we have to interchange the values of both variables.here is the approach code:public int maxProduct(int[] nums) {int maxi = nums[0];int currmax =nums[0];int currmin= nums[0];for(int i=1;i <nums.length;i++){if(nums[i] <0){int temp = currmax;currmax = currmin;currmin = temp;}currmax = Math.max(nums[i],nums[i] *currmax);currmin = Math.min(nums[i],nums[i] *currmin);maxi = Math.max(maxi,currmax);}return maxi;}