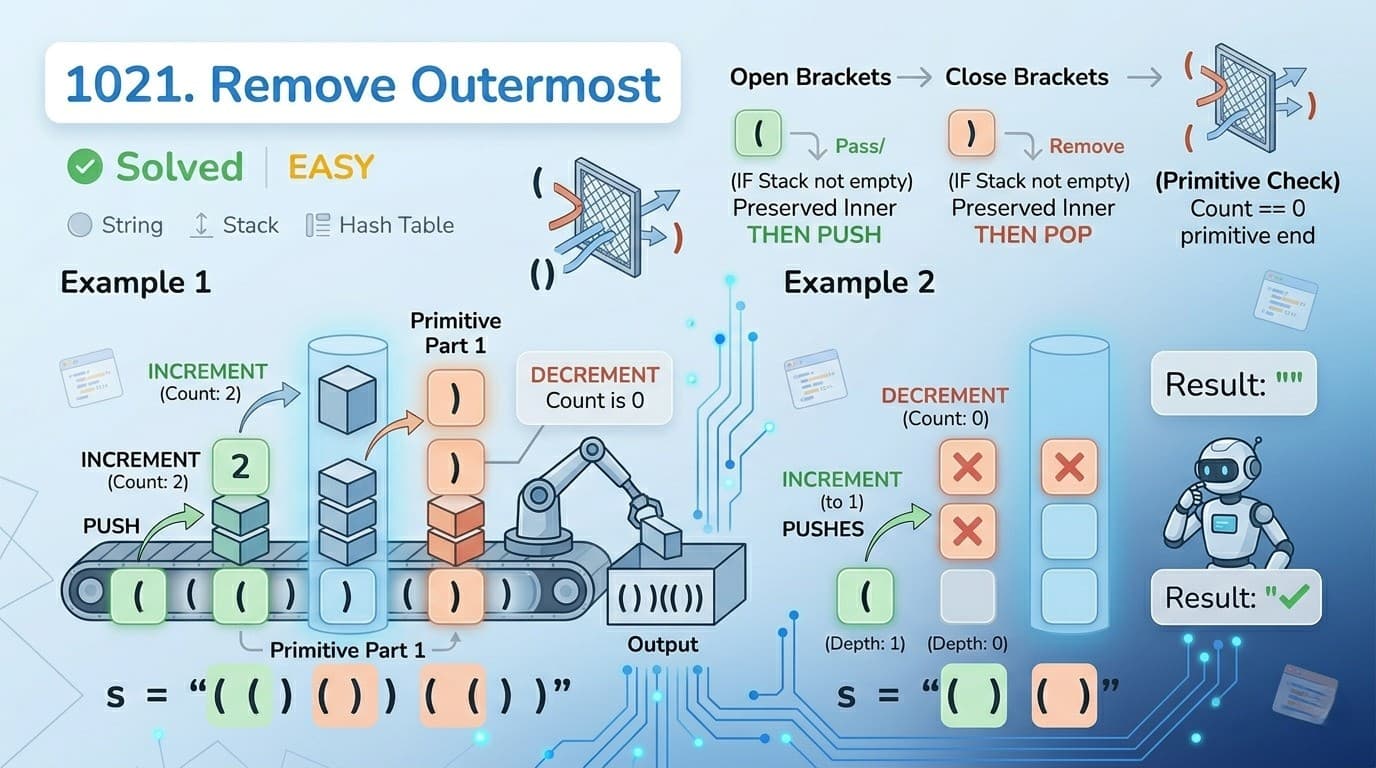
LeetCode 20: Valid Parentheses — Java Solution Explained
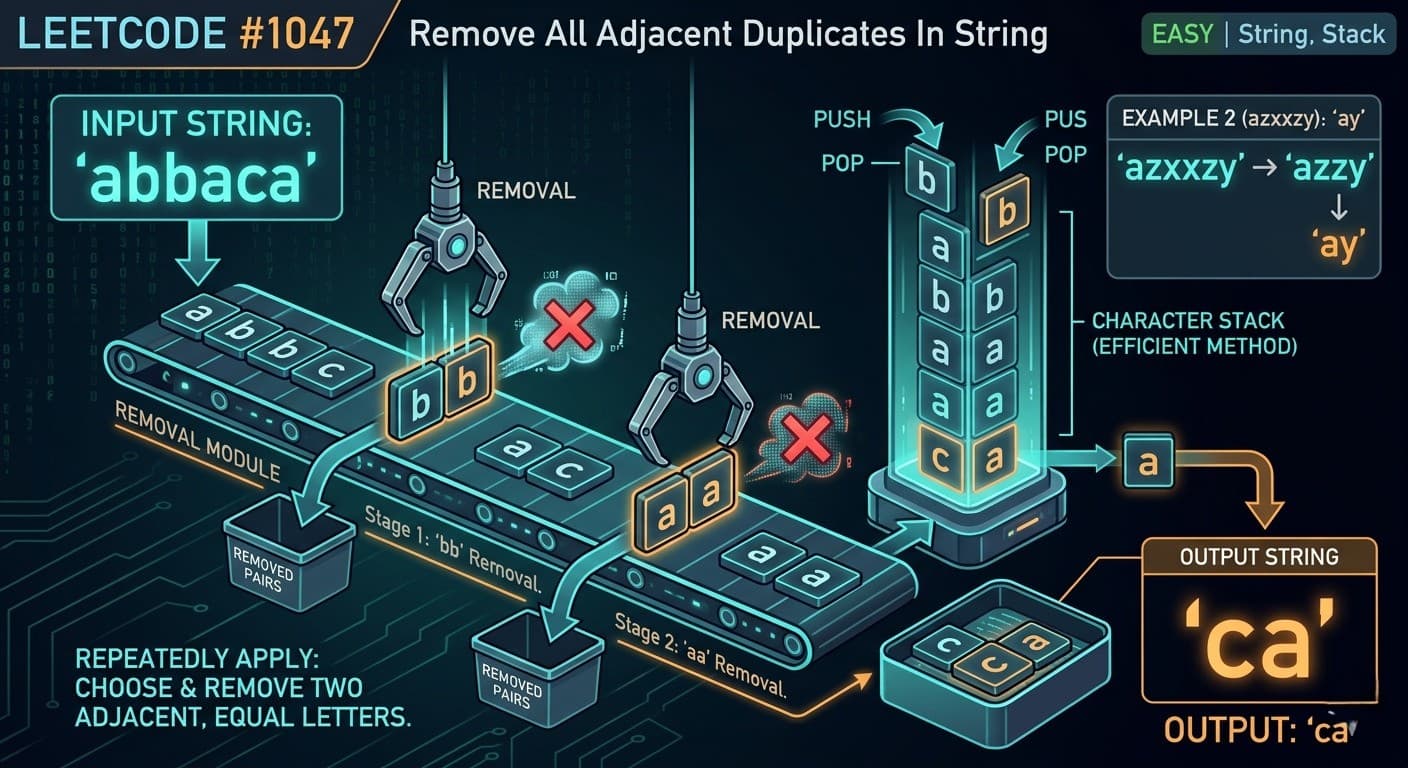
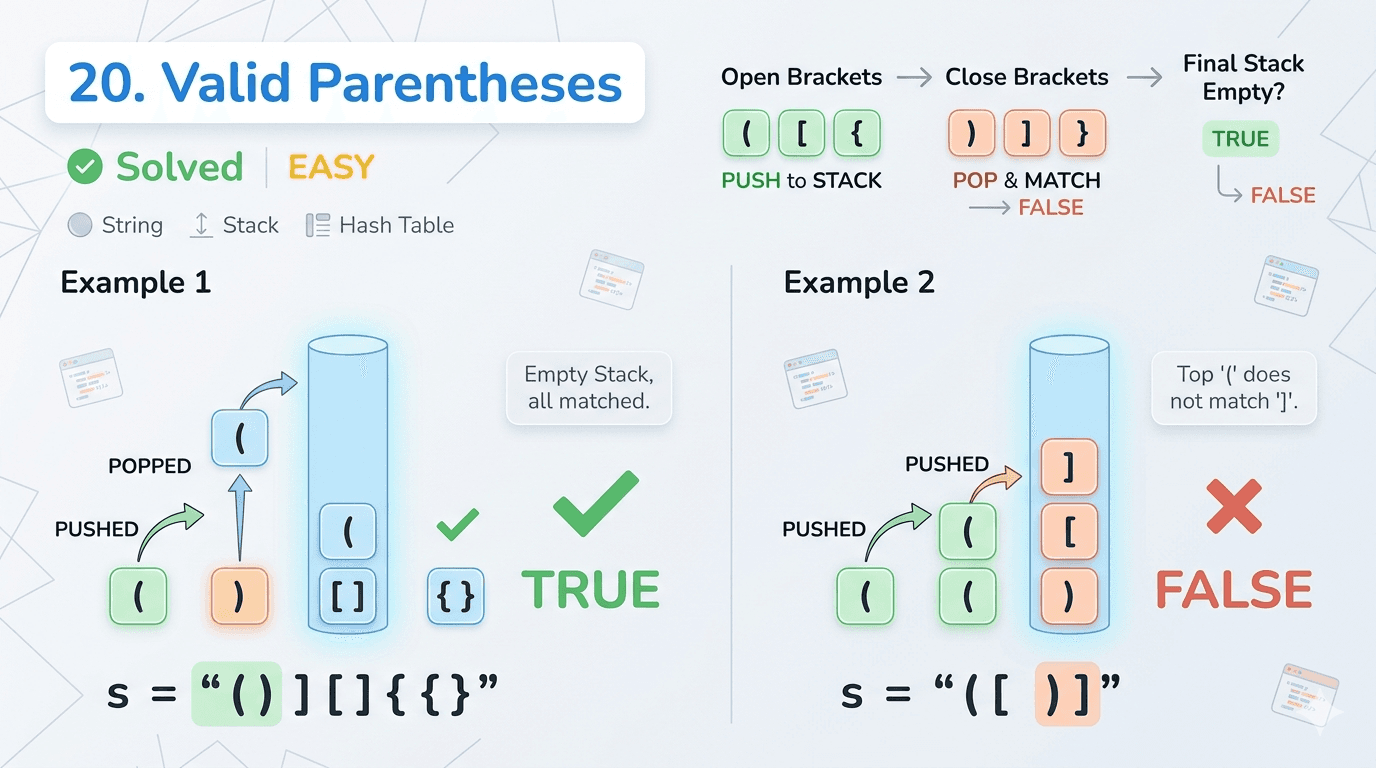
IntroductionLeetCode 20 Valid Parentheses is arguably the single most asked Easy problem in coding interviews. It appears at Google, Amazon, Microsoft, Meta, and virtually every company that does technical interviews. It is the textbook introduction to the Stack data structure and teaches you a pattern that shows up in compilers, code editors, HTML parsers, and mathematical expression evaluators.Here is the Link of Question -: LeetCode 20In this article we cover plain English explanation, real life analogy, the optimal stack solution with detailed dry run, all tricky edge cases, complexity analysis, common mistakes, and FAQs.What Is the Problem Really Asking?You are given a string containing only bracket characters — (, ), {, }, [, ]. You need to check if the brackets are correctly matched and nested.Three rules must hold:Every opening bracket must be closed by the same type of closing bracketBrackets must be closed in the correct order — the most recently opened must be closed firstEvery closing bracket must have a corresponding opening bracketReal Life Analogy — Russian Nesting DollsThink of Russian nesting dolls. You open the biggest doll first, then a medium one inside it, then a small one inside that. To close them back, you must close the smallest first, then medium, then biggest. You cannot close the biggest doll while the smallest is still open inside.That is exactly how brackets work. The last opened bracket must be the first one closed. This Last In First Out behavior is precisely what a Stack is built for.Another analogy — think of a text editor like VS Code. When you type (, it automatically adds ). If you try to close with ] instead, the editor highlights an error. This problem is essentially building that validation logic.The Only Approach You Need: StackThe IdeaScan the string left to rightIf you see an opening bracket → push it onto the stackIf you see a closing bracket → check the top of the stack. If the top is the matching opening bracket, pop it. Otherwise the string is invalid.At the end, if the stack is empty → all brackets matched → return true. If stack still has elements → some brackets were never closed → return false.public boolean isValid(String s) {if (s.length() == 1) return false; // single char can never be validStack<Character> st = new Stack<>();for (int i = 0; i < s.length(); i++) {char c = s.charAt(i);if (c == '(' || c == '{' || c == '[') {st.push(c); // opening bracket — push and wait for its match} else {if (!st.empty()) {// check if top of stack is the matching openerif ((c == ')' && st.peek() != '(') ||(c == '}' && st.peek() != '{') ||(c == ']' && st.peek() != '[')) {return false; // wrong type of closing bracket} else {st.pop(); // matched! remove the opener}} else {return false; // closing bracket with nothing open}}}return st.empty(); // true only if all openers were matched}Detailed Dry Run — s = "([)]"This is the trickiest example. Looks balanced at first glance but is actually invalid.( → opening, push → stack: [(][ → opening, push → stack: [(, []) → closing, peek is [, but ) needs ( → mismatch → return false ✅The stack correctly catches that [ was opened after ( but we tried to close ( before closing [ — wrong order!Dry Run — s = "([{}])"( → push → stack: [(][ → push → stack: [(, []{ → push → stack: [(, [, {]} → peek is {, match! pop → stack: [(, []] → peek is [, match! pop → stack: [(]) → peek is (, match! pop → stack: []Stack is empty → return true ✅Dry Run — s = "(["( → push → stack: [(][ → push → stack: [(, []Loop ends. Stack is NOT empty → return false ✅Two brackets were opened but never closed.All the Edge Cases You Must KnowSingle character like "(" or ")" A single character can never be valid — an opener has nothing to close it, a closer has nothing before it. The early return if (s.length() == 1) return false handles this cleanly.Only closing brackets like "))" The stack is empty when the first ) arrives → return false immediately.Only opening brackets like "(((" All get pushed, nothing gets popped, stack is not empty at end → return false.Interleaved wrong types like "([)]" Caught by the mismatch check when the closing bracket does not match the stack top.Empty string Stack stays empty → st.empty() returns true → returns true. An empty string is technically valid since there are no unmatched brackets. The constraints say length ≥ 1 so this is just good to know.A Cleaner Variation Using HashMapSome developers prefer using a HashMap to store bracket pairs, making the matching condition more readable:public boolean isValid(String s) {Stack<Character> st = new Stack<>();Map<Character, Character> map = new HashMap<>();map.put(')', '(');map.put('}', '{');map.put(']', '[');for (char c : s.toCharArray()) {if (map.containsKey(c)) {// closing bracketif (st.empty() || st.peek() != map.get(c)) {return false;}st.pop();} else {st.push(c); // opening bracket}}return st.empty();}The HashMap maps each closing bracket to its expected opening bracket. This makes adding new bracket types trivial — just add one line to the map. Great for extensibility in real world code.Both versions are O(n) time and O(n) space. Choose whichever feels more readable to you.Time Complexity: O(n) — single pass through the string Space Complexity: O(n) — stack holds at most n/2 opening bracketsWhy Stack Is the Perfect Data Structure HereThe key property this problem exploits is LIFO — Last In First Out. The most recently opened bracket must be the first one closed. That is literally the definition of a stack's behavior.Any time you see a problem where the most recently seen item determines what comes next — think Stack immediately. Valid Parentheses is the purest example of this principle.How This Fits Into the Bigger Stack PatternLooking at everything you have solved so far, notice the pattern evolution:844 Backspace String Compare — # pops the last character 1047 Remove Adjacent Duplicates — matching character pops itself 2390 Removing Stars — * pops the last character 3174 Clear Digits — digit pops the last character 20 Valid Parentheses — closing bracket pops its matching openerAll of these are stack simulations. The difference here is that instead of any character being popped, only the correct matching opener is popped. This matching condition is what makes Valid Parentheses a step up in logic from the previous problems.Common Mistakes to AvoidNot checking if stack is empty before peeking If a closing bracket arrives and the stack is empty, calling peek() throws an EmptyStackException. Always check !st.empty() before peeking or popping.Returning true without checking if stack is empty Even if the loop completes without returning false, unclosed openers remain on the stack. Always return st.empty() at the end, not just true.Pushing closing brackets onto the stack Only push opening brackets. Pushing closing brackets gives completely wrong results and is the most common beginner mistake.Not handling odd length strings If s.length() is odd, it is impossible for all brackets to be matched — you can add if (s.length() % 2 != 0) return false as an early exit for a small optimization.FAQs — People Also AskQ1. Why is a Stack used to solve Valid Parentheses? Because the problem requires LIFO matching — the most recently opened bracket must be the first one closed. Stack's Last In First Out behavior maps perfectly to this requirement, making it the natural and optimal data structure choice.Q2. What is the time complexity of LeetCode 20? O(n) time where n is the length of the string. We make a single pass through the string, and each character is pushed and popped at most once. Space complexity is O(n) in the worst case when all characters are opening brackets.Q3. Can LeetCode 20 be solved without a Stack? Technically yes for simple cases using counters, but only when dealing with a single type of bracket. With three types of brackets that can be nested, a Stack is the only clean solution. Counter-based approaches break down on cases like "([)]".Q4. Is LeetCode 20 asked in FAANG interviews? Absolutely. It is one of the most commonly asked problems across all major tech companies. It tests understanding of the Stack data structure and is often used as a warmup before harder stack problems like Largest Rectangle in Histogram or Decode String.Q5. What happens if the input string has an odd length? An odd-length string can never be valid since brackets always come in pairs. You can add if (s.length() % 2 != 0) return false as an early optimization, though the stack logic handles this correctly on its own.Similar LeetCode Problems to Practice Next1047. Remove All Adjacent Duplicates In String — Easy — stack pattern with characters394. Decode String — Medium — nested brackets with encoding678. Valid Parenthesis String — Medium — wildcards added32. Longest Valid Parentheses — Hard — longest valid substring1249. Minimum Remove to Make Valid Parentheses — Medium — remove minimum brackets to make validConclusionLeetCode 20 Valid Parentheses is the definitive introduction to the Stack data structure in competitive programming and technical interviews. The logic is elegant — push openers, pop on matching closers, check empty at the end. Three rules, one data structure, one pass.Master this problem thoroughly, understand every edge case, and you will have a rock-solid foundation for every stack problem that follows — from Decode String to Largest Rectangle in Histogram.