Mastering Binary Search – LeetCode 704 Explained
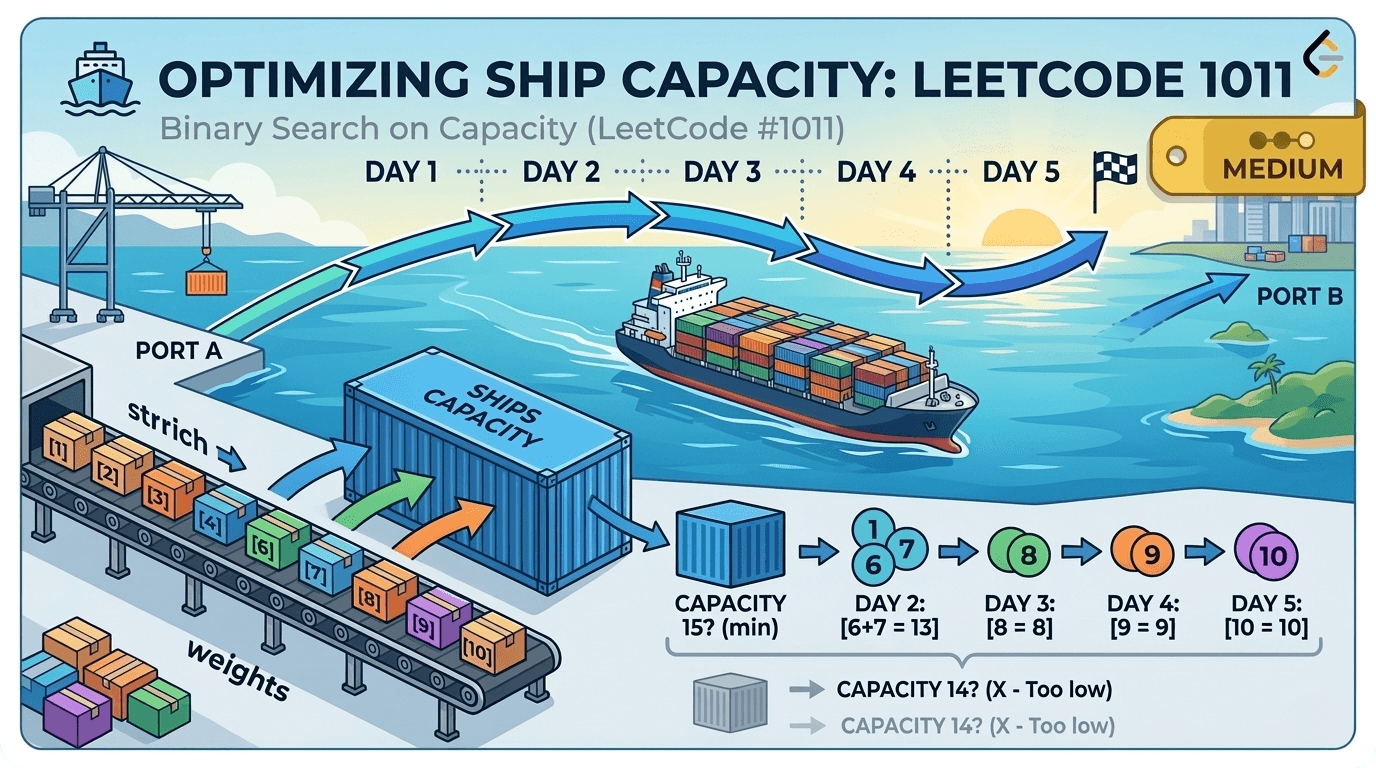
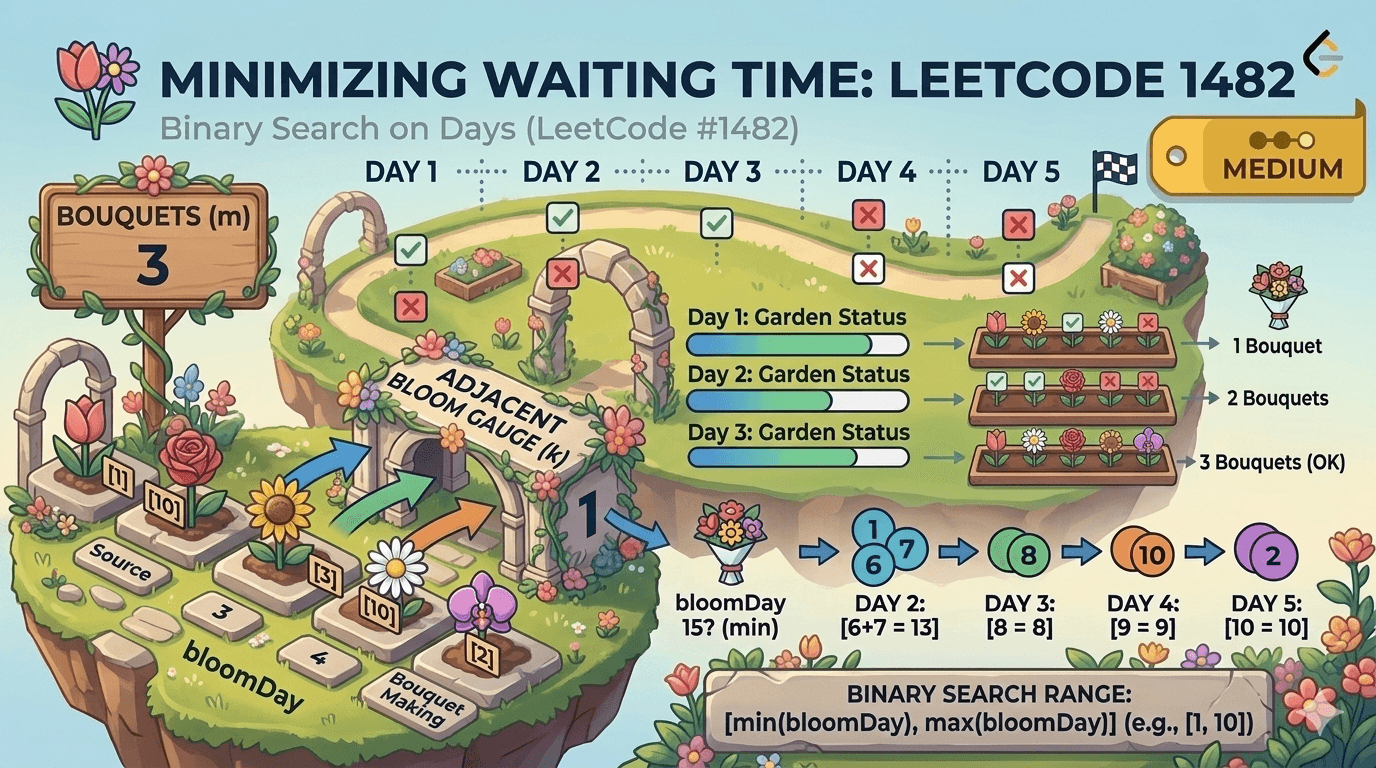
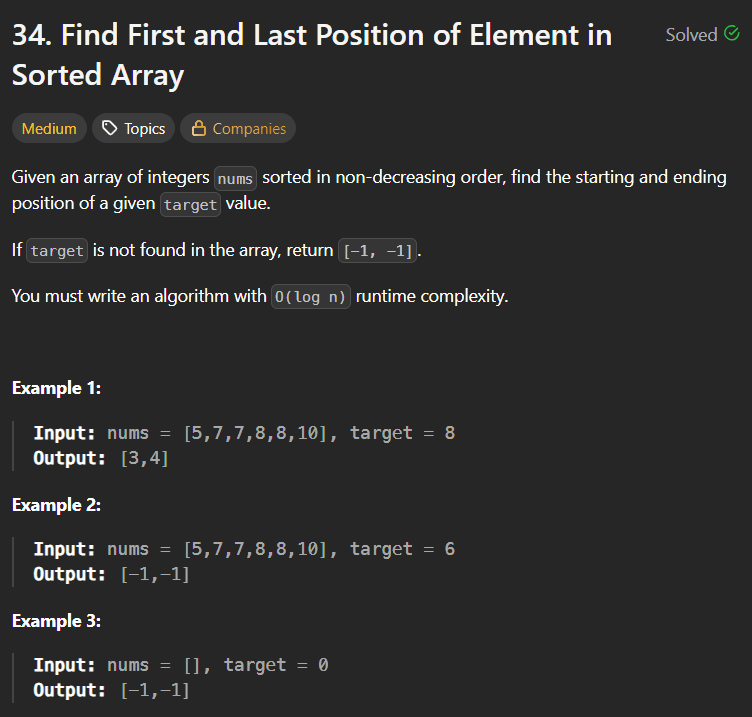
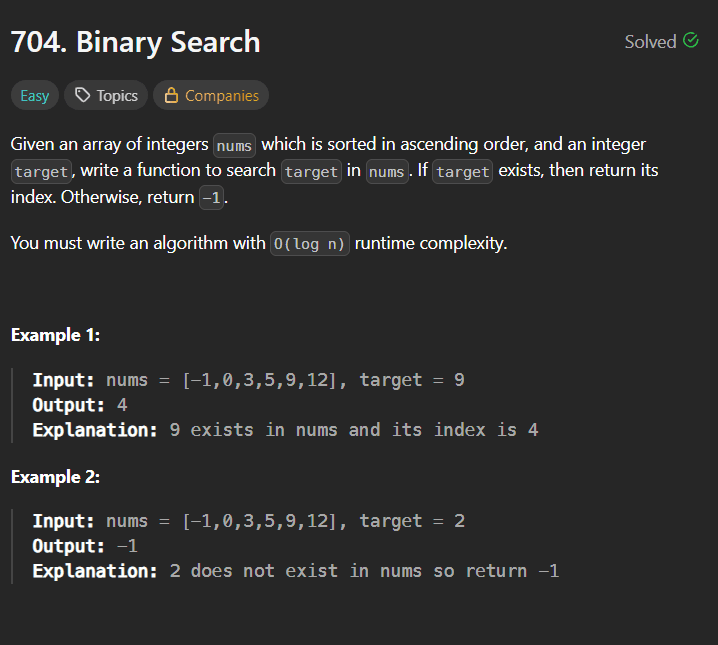
IntroductionBinary Search is one of the most fundamental and powerful algorithms in computer science. If you're preparing for coding interviews, mastering Binary Search is absolutely essential.In this blog, we’ll break down LeetCode 704 – Binary Search, explain the algorithm in detail, walk through your Java implementation, analyze complexity, and recommend additional problems to strengthen your understanding.You can try this problem -: Problem Link📌 Problem OverviewYou are given:A sorted array of integers nums (ascending order)An integer targetYour task is to return the index of target if it exists in the array. Otherwise, return -1.Example 1Input: nums = [-1,0,3,5,9,12], target = 9Output: 4Example 2Input: nums = [-1,0,3,5,9,12], target = 2Output: -1Constraints1 <= nums.length <= 10⁴All integers are uniqueThe array is sorted in ascending orderRequired Time Complexity: O(log n)🚀 Understanding the Binary Search AlgorithmBinary Search works only on sorted arrays.Instead of checking each element one by one (like Linear Search), Binary Search:Finds the middle element.Compares it with the target.Eliminates half of the search space.Repeats until the element is found or the search space is empty.Why is it Efficient?Every iteration cuts the search space in half.If the array size is n, the number of operations becomes:log₂(n)This makes it extremely efficient compared to linear search (O(n)).🧠 Step-by-Step AlgorithmInitialize two pointers:low = 0high = nums.length - 1While low <= high:Calculate middle index:mid = low + (high - low) / 2If nums[mid] == target, return midIf target > nums[mid], search right half → low = mid + 1Else search left half → high = mid - 1If loop ends, return -1💻 Your Java Code ExplainedHere is your implementation:class Solution {public int search(int[] nums, int target) {int high = nums.length-1;int low = 0;while(low <= high){int mid = low+(high-low)/2;if(target == nums[mid] ){return mid;}else if(target > nums[mid]){low = mid+1;}else{high = mid-1;}}return -1;}}🔍 Code Breakdown1️⃣ Initialize Boundariesint high = nums.length - 1;int low = 0;You define the search space from index 0 to n-1.2️⃣ Loop Conditionwhile(low <= high)The loop continues as long as there is a valid search range.3️⃣ Safe Mid Calculationint mid = low + (high - low) / 2;This is preferred over:(low + high) / 2Why?Because (low + high) may cause integer overflow in large arrays.Your approach prevents that.4️⃣ Comparison Logicif(target == nums[mid])If found → return index.else if(target > nums[mid])low = mid + 1;Search in right half.elsehigh = mid - 1;Search in left half.5️⃣ Not Found Casereturn -1;If the loop finishes without finding the target.⏱ Time and Space ComplexityTime Complexity: O(log n)Each iteration halves the search space.Space Complexity: O(1)No extra space used — purely iterative.🔥 Why This Problem Is ImportantLeetCode 704 is:The foundation of all Binary Search problemsA template questionFrequently asked in interviewsRequired to understand advanced problems like:Search in Rotated Sorted ArrayFind First and Last PositionPeak ElementBinary Search on Answer📚 Recommended Binary Search Practice ProblemsAfter solving this, practice these in order:🟢 Easy35. Search Insert Position69. Sqrt(x)278. First Bad Version🟡 Medium34. Find First and Last Position of Element in Sorted Array33. Search in Rotated Sorted Array74. Search a 2D Matrix875. Koko Eating Bananas (Binary Search on Answer)🔴 Advanced Pattern Practice1011. Capacity To Ship Packages Within D Days410. Split Array Largest SumThese will help you master:Lower bound / upper boundBinary search on monotonic functionsSearching in rotated arraysSearching in 2D matricesBinary search on answer pattern🎯 Final ThoughtsBinary Search is not just a single algorithm — it’s a pattern.If you truly understand:How the search space shrinksWhen to move left vs rightHow to calculate mid safelyLoop conditions (low <= high vs low < high)You can solve 50+ interview problems easily.LeetCode 704 is the perfect starting point.Master this template, and you unlock an entire category of problems.